Intelligent document processing (IDP) refers to the automated extraction, classification, and processing of data from various document formats—both structured and unstructured. Within the IDP landscape, key information extraction (KIE) serves as a fundamental component, enabling systems to identify and extract critical data points from documents with minimal human intervention. Organizations across diverse sectors—including financial services, healthcare, legal, and supply chain management—are increasingly adopting IDP solutions to streamline operations, reduce manual data entry, and accelerate business processes. As document volumes grow exponentially, IDP solutions not only automate processing but also enable sophisticated agentic workflows—where AI systems can analyze extracted data and initiate appropriate actions with minimal human intervention. The ability to accurately process invoices, contracts, medical records, and regulatory documents has become not just a competitive advantage but a business necessity. Importantly, developing effective IDP solutions requires not only robust extraction capabilities but also tailored evaluation frameworks that align with specific industry needs and individual organizational use cases.
In this blog post, we demonstrate an end-to-end approach for building and evaluating a KIE solution using Amazon Nova models available through Amazon Bedrock. This end-to-end approach encompasses three critical phases: data readiness (understanding and preparing your documents), solution development (implementing extraction logic with appropriate models), and performance measurement (evaluating accuracy, efficiency, and cost-effectiveness). We illustrate this comprehensive approach using the FATURA dataset—a collection of diverse invoice documents that serves as a representative proxy for real-world enterprise data. By working through this practical example, we show you how to select, implement, and evaluate foundation models for document processing tasks while taking into consideration critical factors such as extraction accuracy, processing speed, and operational costs.
Whether you’re a data scientist exploring generative AI capabilities, a developer implementing document processing pipelines, or a business analyst seeking to understand automation possibilities, this guide provides valuable insights for your use case. By the end of this post, you’ll have a practical understanding of how to use large language models for document extraction tasks, establish meaningful evaluation metrics for your specific use case, and make informed decisions about model selection based on both performance and business considerations. These skills can help your organization move beyond manual document handling toward more efficient, accurate, and scalable document processing solutions.
Dataset
Demonstrating our KIE solution and benchmarking its performance requires a dataset that provides realistic document processing scenarios while offering reliable ground truth for accurate performance measurement. One such dataset is FATURA, which contains 10,000 invoices with 50 distinct layouts (200 invoices per layout). The invoices are all one-page documents stored as JPEG images with annotations of 24 fields per document. High-quality labels are foundational to evaluation tasks, serving as the ground truth against which we measure extraction accuracy. Upon examining the FATURA dataset, we identified several variations in the ground truth labels that required standardization. These included structural inconsistencies (for example, nested versus flat field representations) and value format inconsistencies (for example, prefixed fields like INVOICE DATE: 01/15/2023 or numeric values stored as strings versus floats).
To make sure of fair and accurate evaluation in our study, we normalized these variations by removing inconsistent prefixes and aligning the annotation format with our large language model (LLM) solution’s expected output structure. For this post, we sample 40 documents from 49 distinct layouts for a total of 1,960 samples and shown in the distribution of labels in the following figure, we omit one layout because of several inconsistencies in ground truth annotations. As shown in the figure, the distribution of fields across the samples is notably imbalanced, with occurrences ranging from approximately 250 to 1,800 instances across 18 different fields. This sparsity reflects the real-world nature of documents where not all fields are present in every document—a key challenge for information extraction systems, which must learn to handle missing fields rather than forcing predictions when data is absent.
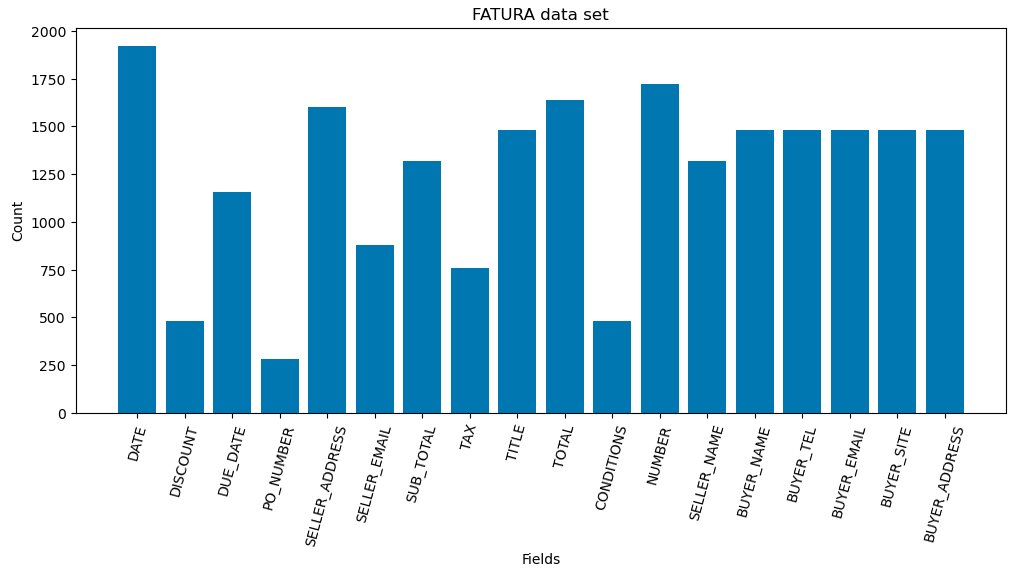
Additional data challenges that practitioners frequently encounter include handling multiple values for a single field (such as several phone numbers listed for contacts), inconsistent representation of missing information (empty strings, N/A, dashes, or other placeholders), dealing with fields that can contain either structured or unstructured text (addresses), and managing value hierarchies where one field might contextually depend on another (tax amounts based on subtotals).
KIE in Amazon Bedrock
Amazon Bedrock can streamline document processing by providing access to LLMs for extracting structured information without complex rule-based systems.
Converse API approach
The Amazon Bedrock Converse API offers a streamlined, unified interface for interacting with foundation models in Amazon Bedrock, significantly simplifying experimentation across different models for document processing tasks. This API removes the complexity of managing model-specific formatting requirements, enabling faster iteration and model comparison for document extraction workflows.
To invoke language models through the Converse API, the required parameters include the model_id to specify which foundation model to use, and the messages containing your prompts and conversation context. The following example demonstrates how to structure this API call, with the next section detailing proper messages formatting techniques.
For comprehensive details on additional parameters, response handling, and best practices, see the Amazon Bedrock Converse API documentation.
Standardized prompt engineering
Effective information extraction requires consistent, model-agnostic prompting strategies that work across different LLMs. Using templating frameworks like Jinja2 enables maintaining a single prompt structure while incorporating rule-based logic. This approach provides flexibility while maintaining consistency across various extraction scenarios.
When designing templates for KIE, consider these logical elements: input variations (textual context types and formats), instruction adjustments for different modalities (image, text, or combined), and field specifications including attributes and pseudonyms. Here’s an example Jinja2 template designed for KIE:
To implement this template in practice, you need to populate it with relevant data before sending it to the LLM. The following code demonstrates how to load your template, insert document-specific data, and generate the final prompt text. The LangChain PromptTemplate loads your Jinja2 file, then a dictionary of key-value pairs supplies the necessary variables, such as optical character recognition (OCR) text from the document and field descriptions. When the format method runs, Jinja2 processes conditional statements and variable substitutions to create the tailored instructions for your specific extraction task:
To handle multiple input modalities in a single request, construct a content array containing the available information sources. For each image, create a formatted entry with proper encoding and add it to the array. Similarly, add the text prompt as another entry. This unified approach accommodates various input combinations—text-only, image-only, or multimodal—without requiring separate handling logic for each case. The following example demonstrates creating this composite input structure:
The image_to_bytes function converts the image provided into a format that the model can understand.
Note, further optimization of image resizing per model might be required for ideal performance.
Measuring performance
When building intelligent document processing solutions, establishing a robust evaluation framework is essential for meeting both technical requirements and business objectives. For KIE, evaluation must go beyond basic accuracy metrics to address the multidimensional nature of document processing. An effective evaluation strategy should include precision and recall measurements, and account for the varying importance of different fields correctly extracting a total amount might be more critical than capturing a memo field. Practical considerations such as processing latency and cost per document must also factor into your evaluation matrix. Using the FATURA dataset, we’ll demonstrate how to construct metrics that balance technical performance with business value, so you too can quantify not only extraction accuracy, but also how effectively your solution addresses your organization’s specific document processing needs.
F1-score
For our KIE solution, we evaluate performance using the F1-score, which balances the system’s precision (correctness of extracted values) and recall (ability to find the relevant fields) to provide a comprehensive assessment of extraction accuracy. To calculate the F1-score, we need to accurately classify each extraction attempt as a true positive, false positive, or false negative. This classification hinges on a critical question: does the extracted value match the ground truth? For document processing, this seemingly simple comparison is complicated by the diverse nature of extracted information—dates might be formatted differently but represent the same day, or monetary values might include different currency symbols while being numerically identical.
This challenge necessitates field-specific comparators that intelligently determine when an extraction counts as a match. Here are a few:
- Numeric fields: Allow formatting variations while matching actual values
- Text fields: Apply fuzzy matching for spacing or punctuation differences
- Structured fields: Normalize formats for dates, addresses, and other structured data with variable representations before comparison
With these comparators established, we classify each extraction attempt into one of four categories:
- True positive (TP): The field exists in the ground truth and our system correctly extracted its value according to the field-specific comparator
- False positive (FP): Our system extracted a value for a field, but either the field doesn’t exist in the ground truth or the extracted value doesn’t match the expected value
- False negative (FN): The field exists in the ground truth, but our system failed to extract it
- True negative (TN): The field doesn’t exist in the ground truth, and our system correctly didn’t extract it
These values are used to calculate precision (TP/(TP+FP)) and recall (TP/(TP+FN)), combining them into the F1-score: 2 × (precision × recall)/(precision + recall). This approach provides a comprehensive evaluation that balances the system’s ability to find relevant information with its ability to avoid incorrect extractions.
Latency and cost
When implementing IDP solutions, latency and cost considerations are just as critical as extraction accuracy. These operational metrics directly impact both user experience and the economic viability of your document processing pipeline. Amazon Bedrock simplifies performance monitoring by including key metrics with every model response. Each time you invoke a foundation model, the response contains metadata on input tokens, output tokens, and processing latency in milliseconds. Using this built-in instrumentation, teams can track performance without implementing additional monitoring infrastructure. The following is a subset of the response syntax template (more information can be found in Converse):
Latency in Amazon Bedrock represents the model’s response time—how quickly it processes your document and generates extraction results. Smaller models within a model family typically process documents faster than larger variants, though this varies based on document complexity. This processing time directly impacts how quickly extracted information becomes available for downstream business processes.
Cost in Amazon Bedrock is determined by token usage, following a straightforward formula: ![[ "input tokens" /1000 ]*"price per 1000 input tokens + "[ "output tokens" /1000 ]*"price per 1000 output tokens"](https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b1b99f41ad8b103eff4b59/2025/08/28/Screenshot-2025-08-27-at-9.16.07%E2%80%AFPM.png)
Each model uses its own tokenizer, so token counts vary between models even for identical documents. Pricing information for Amazon Bedrock models is available at Amazon Bedrock Pricing.
Because document length varies significantly across business contexts—from single-page receipts to hundred-page contracts—comparing performance metrics at the document level can be misleading. Normalizing latency and cost to a standard unit, such as per 1,000 pages, creates a consistent benchmark for evaluation. This standardized approach enables meaningful comparisons between different models, document types, and processing strategies. For instance, knowing that a solution processes documents at $15 per 1,000 pages with an average latency of 2.3 seconds per page provides a scalable understanding of operational costs and performance implications, regardless of individual document length.
By systematically tracking these metrics across different document types, organizations can make informed decisions that balance extraction quality, processing speed, and operational costs based on their specific business requirements.
Performance analysis: F1 score, latency, and cost trade-offs
We conducted a comprehensive evaluation of intelligent document processing performance on the FATURA dataset across three dimensions: extraction accuracy (F1 score), processing speed (latency), and operational expenses (cost). Our analysis compared two models from the Nova family, representing both a lighter, smaller model and a larger, more capable model. We selected specific models from each family because of their multimodal capabilities, allowing us to evaluate performance across text, image, and combined modalities.
Accuracy performance
As expected, the larger model achieved higher extraction accuracy than the smaller counterpart. Amazon Nova Pro achieved the highest overall F1 score (0.9793) when using both text and image inputs.Across both models in this evaluation, text-only processing typically delivered the strongest extraction accuracy, with text and image combinations performing similarly or slightly lower. Image-only processing consistently achieved the lowest F1 scores in our tests.Breaking down accuracy by specific fields provides deeper insights into model performance. Field-level analysis often reveals that certain information types—such as dates, invoice numbers, or line items—might have significantly different extraction success rates even within the same model. This granular evaluation helps identify which fields require prompt optimization or additional model tuning. For example, a model might excel at extracting total amounts but struggle with vendor addresses. Such field-specific error analysis enables targeted improvements to prompting strategies and extraction techniques, ultimately enhancing overall system performance.
Latency considerations
In line with expectations, the smaller model, Amazon Nova Lite, delivered faster processing. Image processing typically required additional processing time, particularly for larger models, reflecting the additional complexity of visual information extraction for Amazon Nova Pro.
Cost efficiency
Cost varied dramatically across these two models, with an over 20-fold difference between the most and least expensive options per 1,000 pages:
- Nova Lite was the most economical, with costs well under $0.50 per 1,000 pages
- Adding image processing generally increased costs due to higher input token counts
Optimal configuration analysis
Our evaluation highlights why organizations should weigh accuracy, speed, and cost metrics together when selecting foundation models for document processing. While these findings provide valuable insights, they are specific to the FATURA dataset—organizations should conduct similar evaluations on their own document types to determine the optimal model and modality combinations for their specific business needs.
The following table shows performance, latency, and cost comparisons from the Amazon Nova model family and across three input modalities.
| Model | Modality | F1 score | Latency per page | Avg input/output token | Cost per 1,000 pages |
| Nova Lite | Image | 0.8799 | 4.63 | 3773/305 | $0.2996 |
| Text | 0.9222 | 3.07 | 2340/316 | $0.2162 | |
| Both | 0.9019 | 4.81 | 4090/311 | $0.3200 | |
| Nova Pro | Image | 0.9324 | 10.99 | 3773/305 | $3.9944 |
| Text | 0.9784 | 5.19 | 2340/316 | $2.8832 | |
| Both | 0.9793 | 11.12 | 4090/311 | $4.2672 |
Conclusion
Our exploration of intelligent document processing using foundation models available through Amazon Bedrock demonstrates the critical importance of a holistic approach—from data preparation through implementation to comprehensive evaluation. The three-dimensional framework—measuring accuracy, latency, and cost—enables organizations to assess IDP solutions comprehensively and develop document processing systems that align with their specific business objectives. The analysis reveals a key insight: while larger models generally achieve higher accuracy, smaller models can deliver impressive results at a fraction of the cost, highlighting the essential balance organizations must strike between performance and operational efficiency. As document volumes continue growing across industries, this end-to-end approach empowers data scientists, developers, and business analysts to implement IDP solutions that transform document handling from a manual burden into a strategic advantage—delivering the right balance of accuracy and efficiency for your specific organizational needs. In upcoming work, we’ll expand our benchmarking to more diverse and challenging document types across various domains and industries. We’ll also explore how fine-tuning these foundation models on domain-specific data can enhance extraction accuracy and performance for specialized use cases—enabling organizations to build IDP solutions that more precisely address their unique business challenges and document processing requirements.
Ready to transform your document processing workflow? Get started with Amazon Bedrock by visiting What is Amazon Bedrock. Follow the steps outlined in this post to evaluate how these foundation models perform on your own documents and begin building a tailored IDP solution that addresses your unique business challenges.
About the authors
 Ayushi Haria is a Deep Learning Architect at Amazon Web Services (AWS), where she has worked for over two years following an earlier internship. For the past year, she has been a member of AWS’s Generative AI Innovation Center (GenAIIC), where she specializes in intelligent document processing and evaluation methods.
Ayushi Haria is a Deep Learning Architect at Amazon Web Services (AWS), where she has worked for over two years following an earlier internship. For the past year, she has been a member of AWS’s Generative AI Innovation Center (GenAIIC), where she specializes in intelligent document processing and evaluation methods.
 Sujitha Martin is an Senior Applied Scientist in the Generative AI Innovation Center (GenAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. Her research spans from developing human-centered situational awareness for highly autonomous systems to designing customizable intelligent document processing solutions.
Sujitha Martin is an Senior Applied Scientist in the Generative AI Innovation Center (GenAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. Her research spans from developing human-centered situational awareness for highly autonomous systems to designing customizable intelligent document processing solutions.
 Spencer Romo is a Senior Data Scientist specializing in intelligent document processing, with deep expertise across computer vision, NLP, and signal processing. His innovative work in remote sensing has led to multiple patents. Based in Austin, Texas, he partners closely with customers to deliver impactful AI solutions. Outside of work, Spencer competes in the 24 Hours of Lemons racing series, combining his passion for engineering with budget-conscious motorsports.
Spencer Romo is a Senior Data Scientist specializing in intelligent document processing, with deep expertise across computer vision, NLP, and signal processing. His innovative work in remote sensing has led to multiple patents. Based in Austin, Texas, he partners closely with customers to deliver impactful AI solutions. Outside of work, Spencer competes in the 24 Hours of Lemons racing series, combining his passion for engineering with budget-conscious motorsports.
 Jared Kramer is an Applied Science Manager at Amazon Web Services based in Seattle. Jared joined Amazon 11 years ago as an ML Science intern. He currently leads of team of Applied Scientists and Deep Learning Architects in the Generative AI Innovation Center, having previously spent 6 years in Customer Service Technologies and 4 years in Sustainability Science and Innovation.
Jared Kramer is an Applied Science Manager at Amazon Web Services based in Seattle. Jared joined Amazon 11 years ago as an ML Science intern. He currently leads of team of Applied Scientists and Deep Learning Architects in the Generative AI Innovation Center, having previously spent 6 years in Customer Service Technologies and 4 years in Sustainability Science and Innovation.