Supercharge generative AI workflows with NVIDIA DGX Cloud on AWS and Amazon Bedrock Custom Model Import
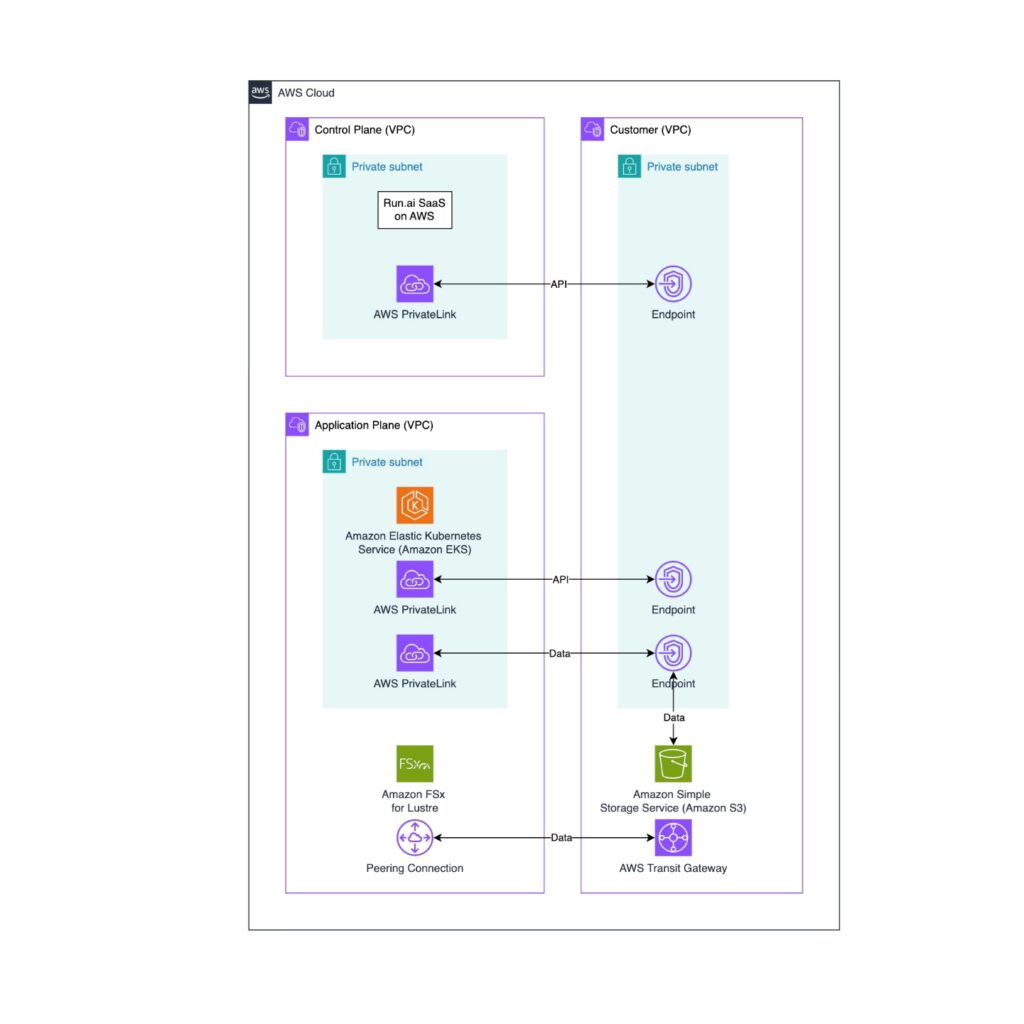
This post is co-written with Andrew Liu, Chelsea Isaac, Zoey Zhang, and Charlie Huang from NVIDIA. DGX Cloud on Amazon Web Services (AWS) represents a significant leap forward in democratizing access to high-performance AI infrastructure. By combining NVIDIA GPU expertise with AWS scalable cloud services, organizations can accelerate their time-to-train, reduce operational complexity, and unlock […]
Accelerate generative AI inference with NVIDIA Dynamo and Amazon EKS
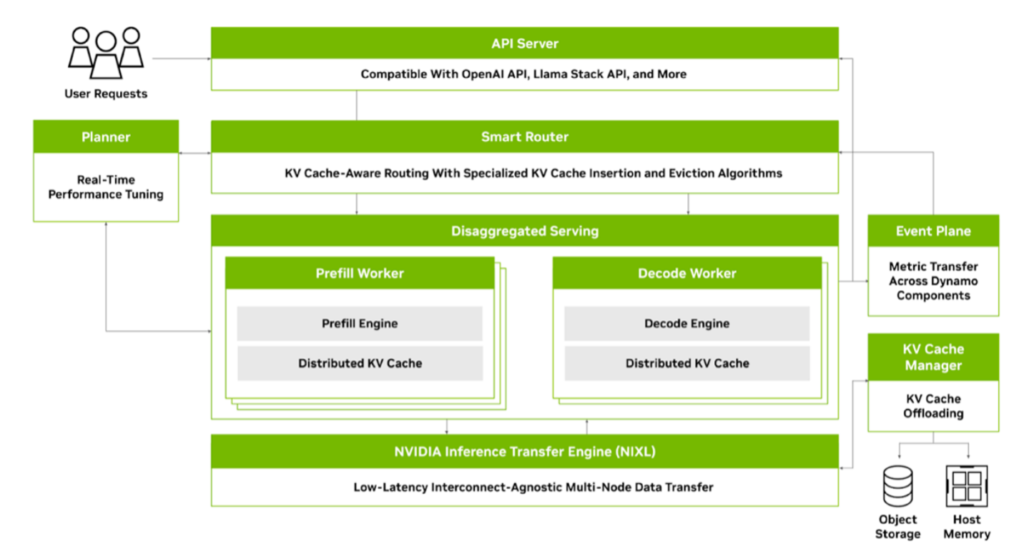
This post is co-written with Kshitiz Gupta, Wenhan Tan, Arun Raman, Jiahong Liu, and Eiluth Triana Isaza from NVIDIA. As large language models (LLMs) and generative AI applications become increasingly prevalent, the demand for efficient, scalable, and low-latency inference solutions has grown. Traditional inference systems often struggle to meet these demands, especially in distributed, multi-node […]
AWS doubles investment in AWS Generative AI Innovation Center, marking two years of customer success

When we launched the AWS Generative AI Innovation Center in 2023, we had one clear goal: help customers turn AI potential into real business value. We’ve already guided thousands of customers across industries from financial services to healthcare—including Formula 1, FOX, GovTech Singapore, Itaú Unibanco, Nasdaq, NFL, RyanAir, and S&P Global—from AI experimentation to full-scale […]
Build AI-driven policy creation for vehicle data collection and automation using Amazon Bedrock
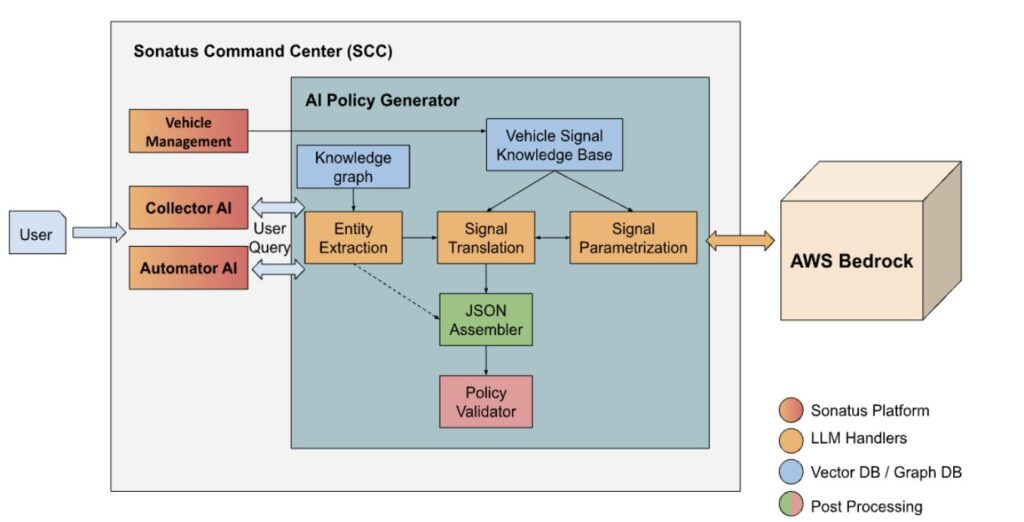
Vehicle data is critical for original equipment manufacturers (OEMs) to drive continuous product innovation and performance improvements and to support new value-added services. Similarly, the increasing digitalization of vehicle architectures and adoption of software-configurable functions allow OEMs to add new features and capabilities efficiently. Sonatus’s Collector AI and Automator AI products address these two aspects […]
How Rapid7 automates vulnerability risk scores with ML pipelines using Amazon SageMaker AI
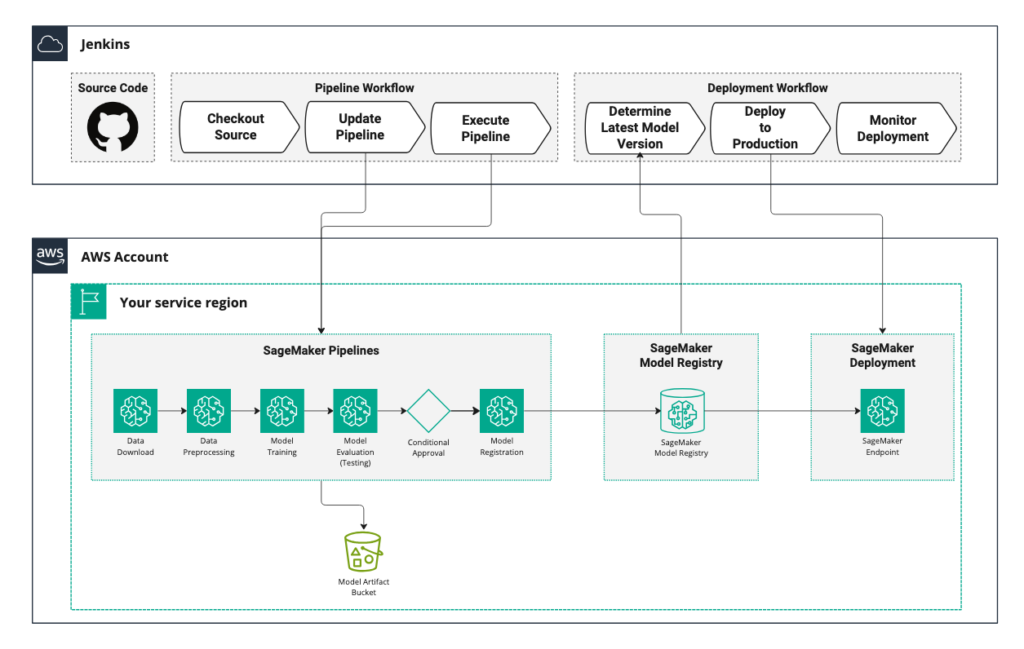
This post is cowritten with Jimmy Cancilla from Rapid7. Organizations are managing increasingly distributed systems, which span on-premises infrastructure, cloud services, and edge devices. As systems become interconnected and exchange data, the potential pathways for exploitation multiply, and vulnerability management becomes critical to managing risk. Vulnerability management (VM) is the process of identifying, classifying, prioritizing, […]
Build secure RAG applications with AWS serverless data lakes
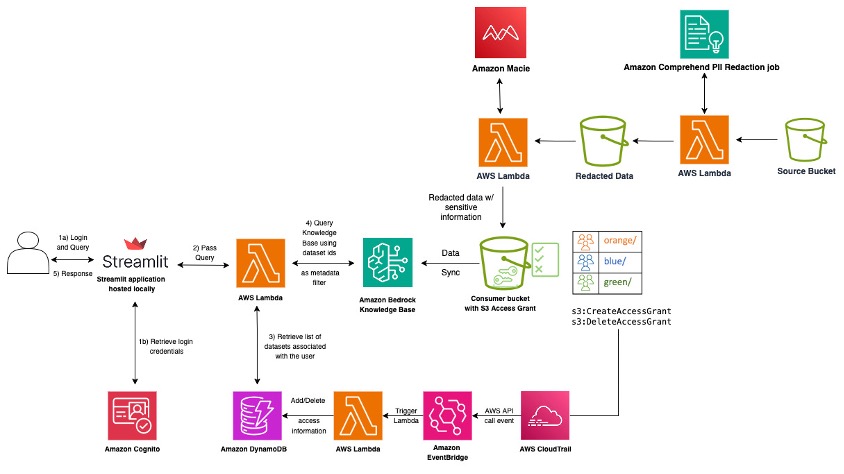
Data is your generative AI differentiator, and successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Traditional data architectures often struggle to meet the unique demands of generative such as applications. An effective generative AI data strategy requires several key components like seamless integration of diverse data sources, […]
Advanced fine-tuning methods on Amazon SageMaker AI

This post provides the theoretical foundation and practical insights needed to navigate the complexities of LLM development on Amazon SageMaker AI, helping organizations make optimal choices for their specific use cases, resource constraints, and business objectives. We also address the three fundamental aspects of LLM development: the core lifecycle stages, the spectrum of fine-tuning methodologies, […]
Streamline machine learning workflows with SkyPilot on Amazon SageMaker HyperPod
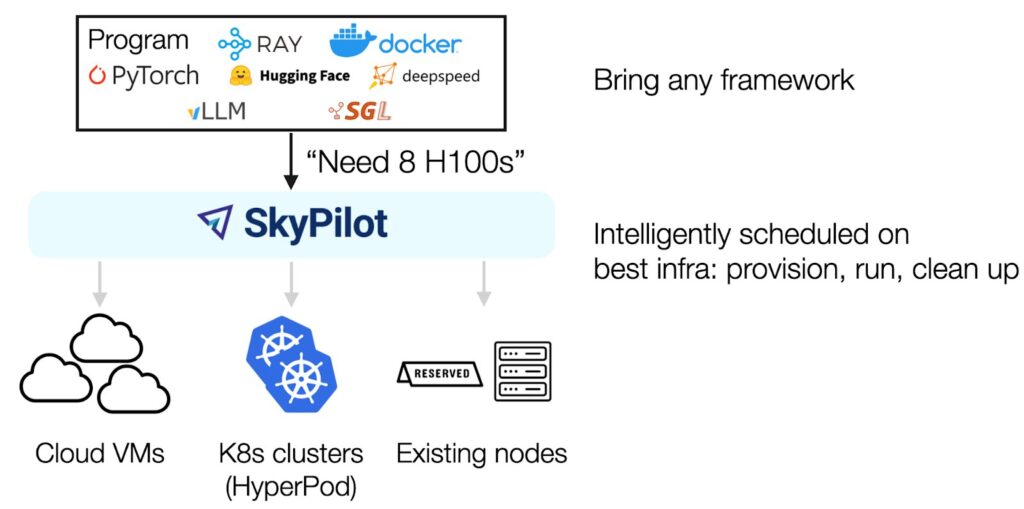
This post is co-written with Zhanghao Wu, co-creator of SkyPilot. The rapid advancement of generative AI and foundation models (FMs) has significantly increased computational resource requirements for machine learning (ML) workloads. Modern ML pipelines require efficient systems for distributing workloads across accelerated compute resources, while making sure developer productivity remains high. Organizations need infrastructure solutions […]
Intelligent document processing at scale with generative AI and Amazon Bedrock Data Automation
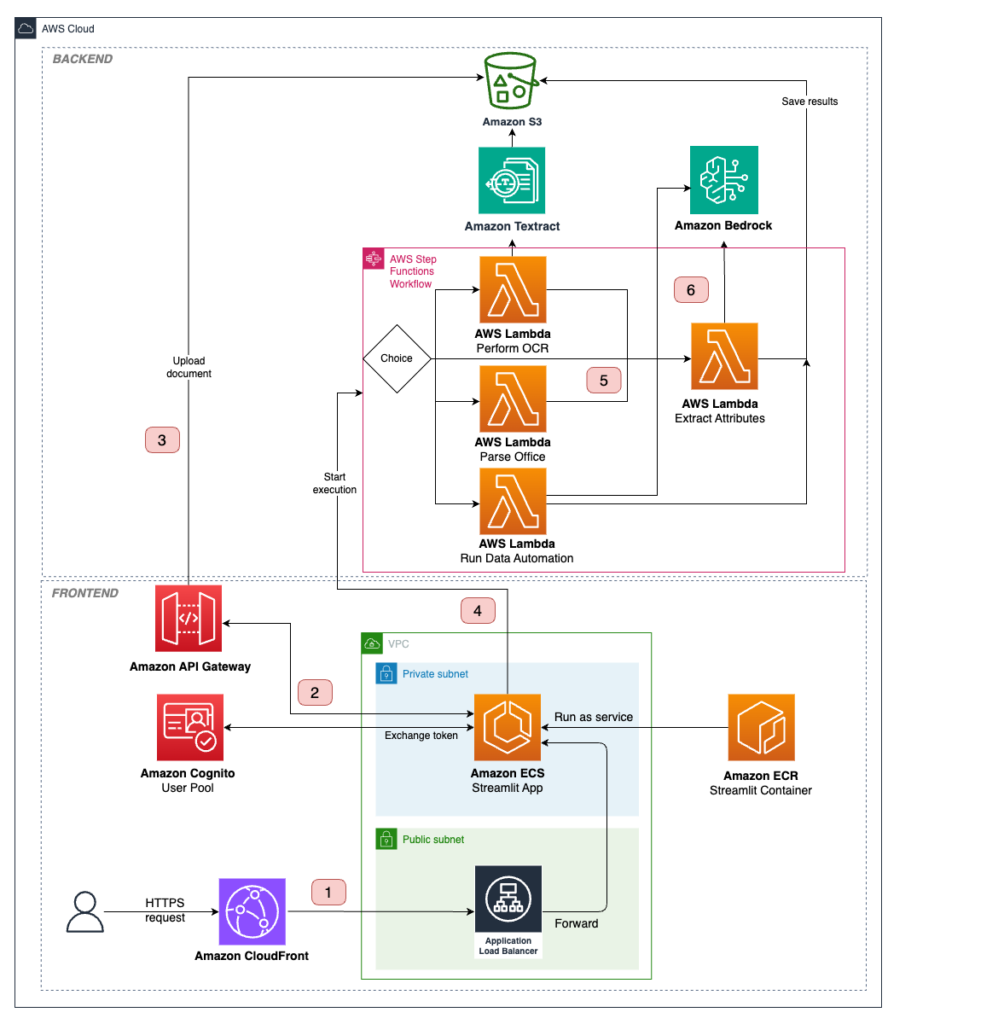
Extracting information from unstructured documents at scale is a recurring business task. Common use cases include creating product feature tables from descriptions, extracting metadata from documents, and analyzing legal contracts, customer reviews, news articles, and more. A classic approach to extracting information from text is named entity recognition (NER). NER identifies entities from predefined categories, […]
Build a conversational data assistant, Part 2 – Embedding generative business intelligence with Amazon Q in QuickSight
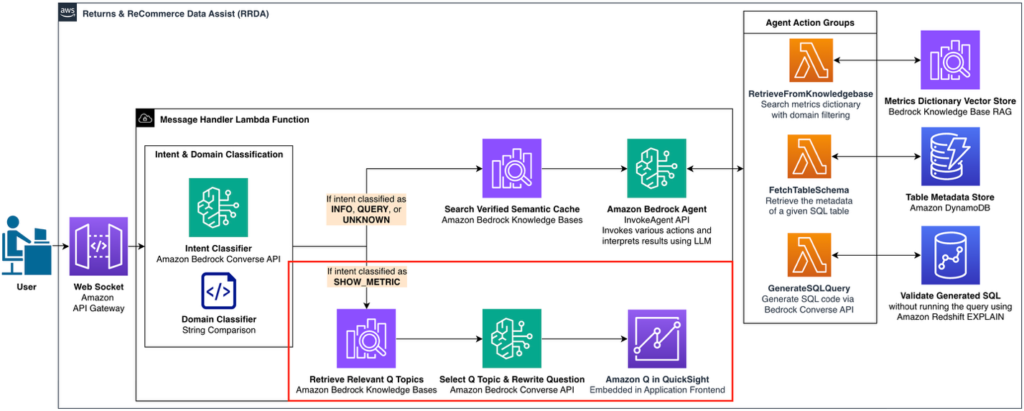
In Part 1 of this series, we explored how Amazon’s Worldwide Returns & ReCommerce (WWRR) organization built the Returns & ReCommerce Data Assist (RRDA)—a generative AI solution that transforms natural language questions into validated SQL queries using Amazon Bedrock Agents. Although this capability improves data access for technical users, the WWRR organization’s journey toward truly […]