Deploy Amazon Bedrock Knowledge Bases using Terraform for RAG-based generative AI applications
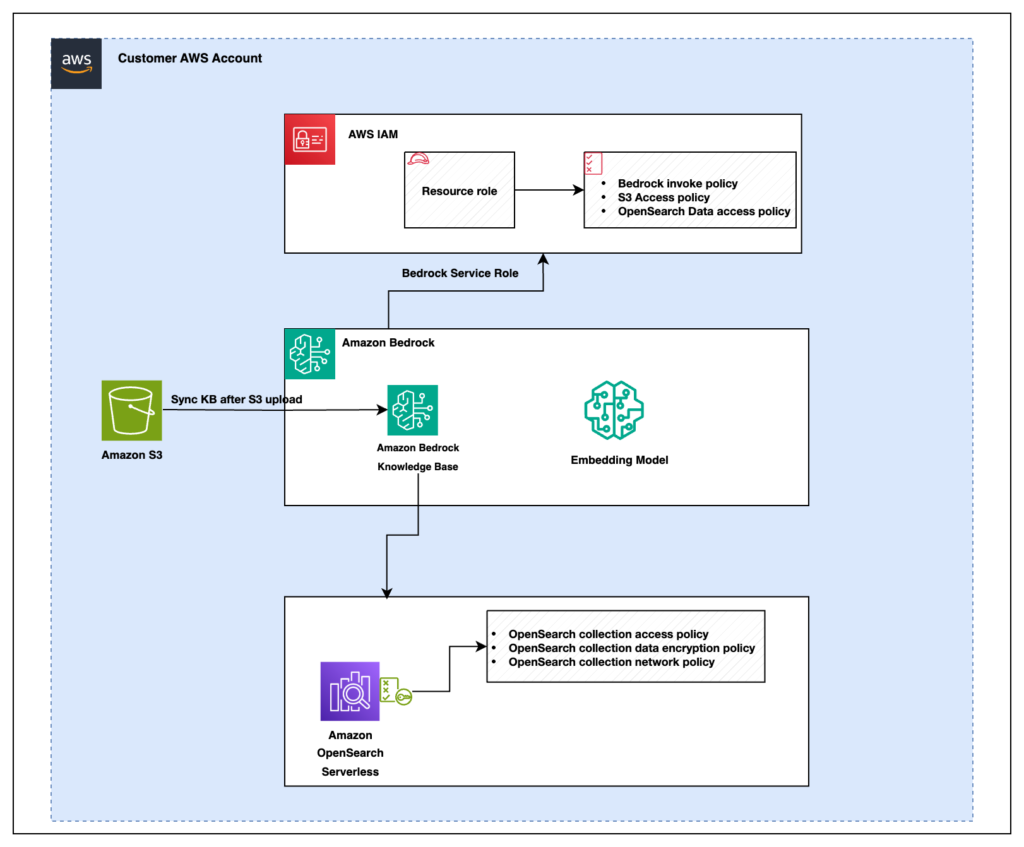
Retrieval Augmented Generation (RAG) is a powerful approach for building generative AI applications by providing foundation models (FMs) access to additional, relevant data. This approach improves response accuracy and transparency while avoiding the potential cost and complexity of FM training or fine-tuning. Many customers use Amazon Bedrock Knowledge Bases to help implement RAG workflows. You […]
Document intelligence evolved: Building and evaluating KIE solutions that scale
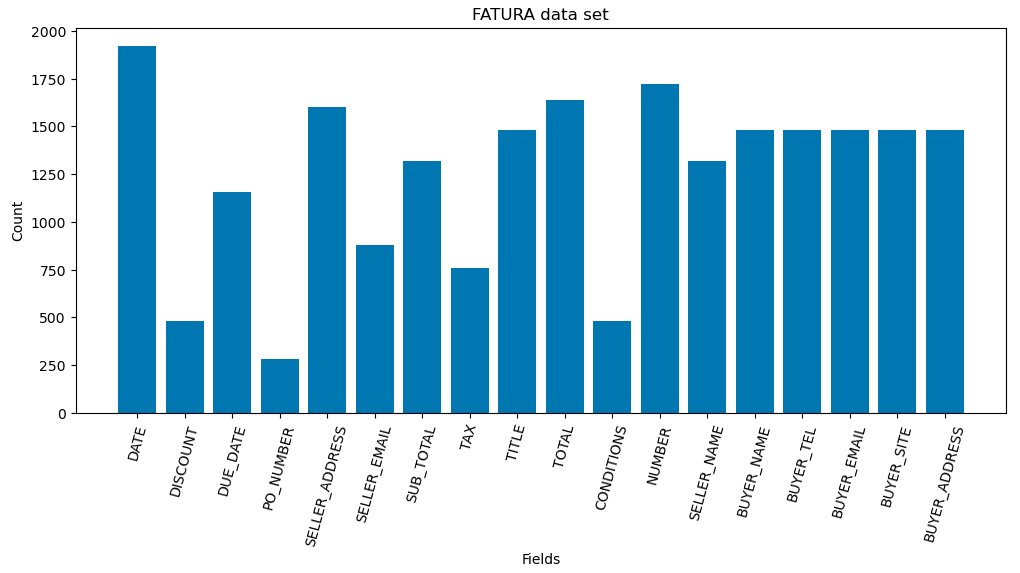
Intelligent document processing (IDP) refers to the automated extraction, classification, and processing of data from various document formats—both structured and unstructured. Within the IDP landscape, key information extraction (KIE) serves as a fundamental component, enabling systems to identify and extract critical data points from documents with minimal human intervention. Organizations across diverse sectors—including financial services, […]
Announcing the new cluster creation experience for Amazon SageMaker HyperPod
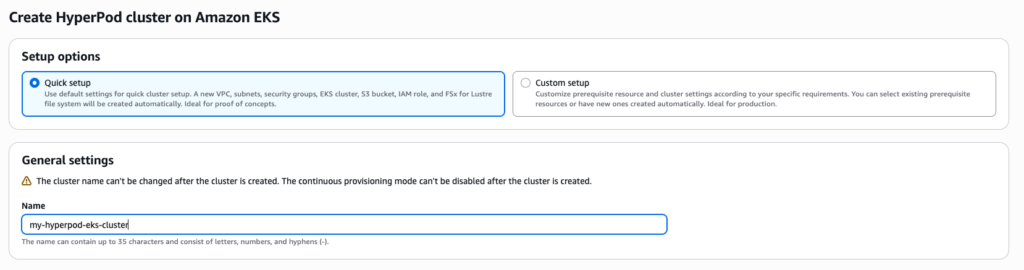
Today, Amazon SageMaker HyperPod is announcing a new one-click, validated cluster creation experience that accelerates setup and prevents common misconfigurations, so you can launch your distributed training and inference clusters complete with Slurm or Amazon Elastic Kubernetes Service (Amazon EKS) orchestration, Amazon Virtual Private Cloud (Amazon VPC) networking, high-performance storage, and security built in by […]
Detect Amazon Bedrock misconfigurations with Datadog Cloud Security
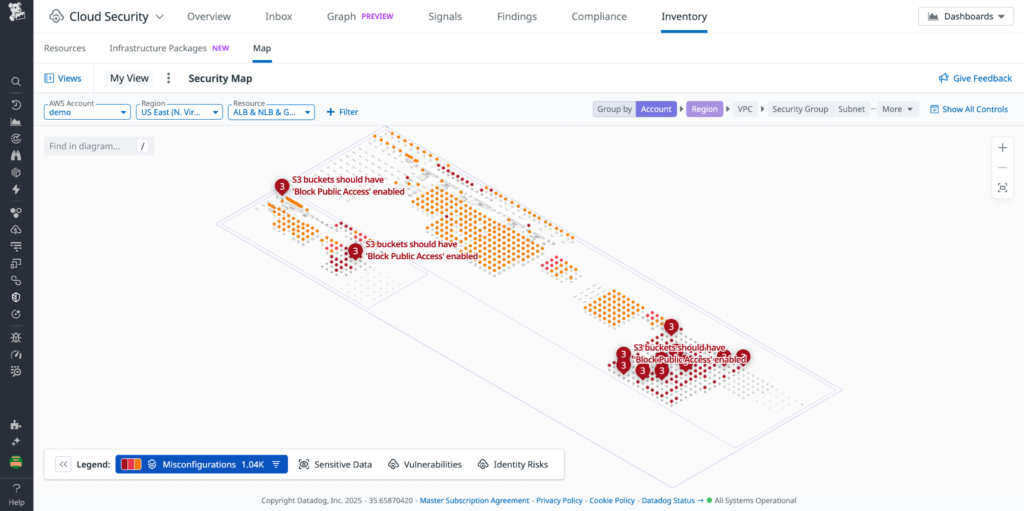
This post was co-written with Nick Frichette and Vijay George from Datadog. As organizations increasingly adopt Amazon Bedrock for generative AI applications, protecting against misconfigurations that could lead to data leaks or unauthorized model access becomes critical. The AWS Generative AI Adoption Index, which surveyed 3,739 senior IT decision-makers across nine countries, revealed that 45% […]
Set up custom domain names for Amazon Bedrock AgentCore Runtime agents
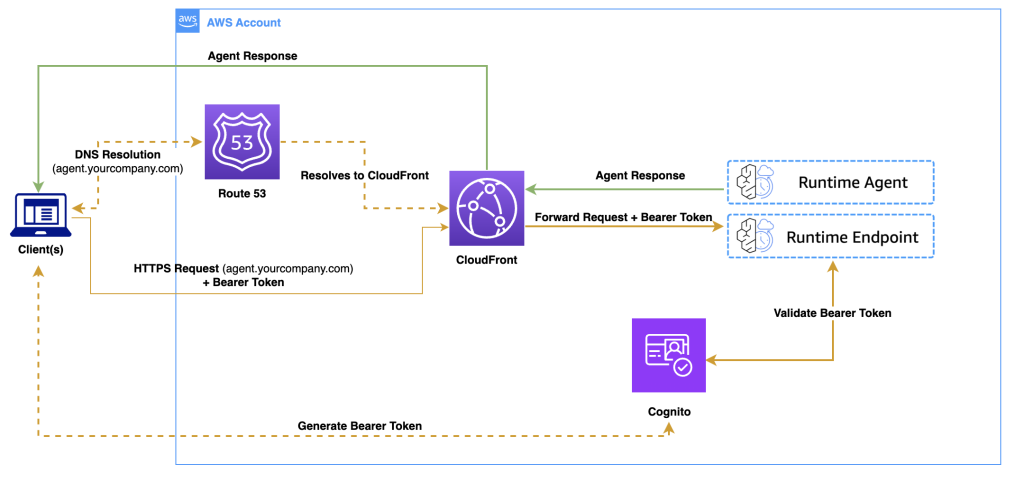
When deploying AI agents to Amazon Bedrock AgentCore Runtime (currently in preview), customers often want to use custom domain names to create a professional and seamless experience. By default, AgentCore Runtime agents use endpoints like https://bedrock-agentcore.{region}.amazonaws.com/runtimes/{EncodedAgentARN}/invocations. In this post, we discuss how to transform these endpoints into user-friendly custom domains (like https://agent.yourcompany.com) using Amazon CloudFront […]
Introducing auto scaling on Amazon SageMaker HyperPod
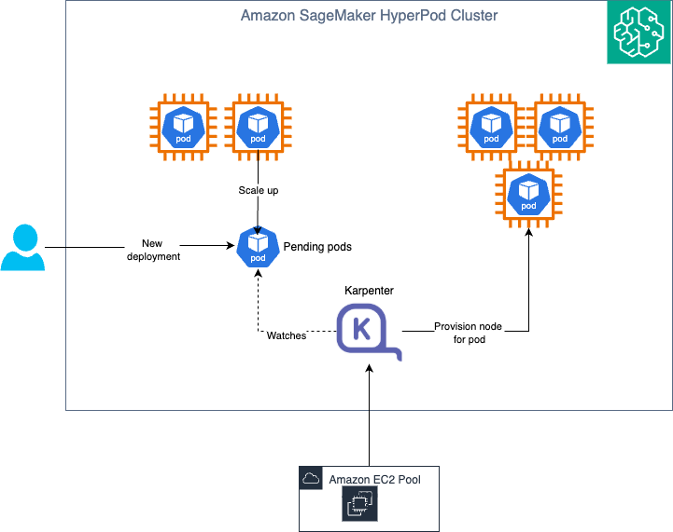
Today, we’re excited to announce that Amazon SageMaker HyperPod now supports managed node automatic scaling with Karpenter, so you can efficiently scale your SageMaker HyperPod clusters to meet your inference and training demands. Real-time inference workloads require automatic scaling to address unpredictable traffic patterns and maintain service level agreements (SLAs). As demand spikes, organizations must […]
Meet Boti: The AI assistant transforming how the citizens of Buenos Aires access government information with Amazon Bedrock
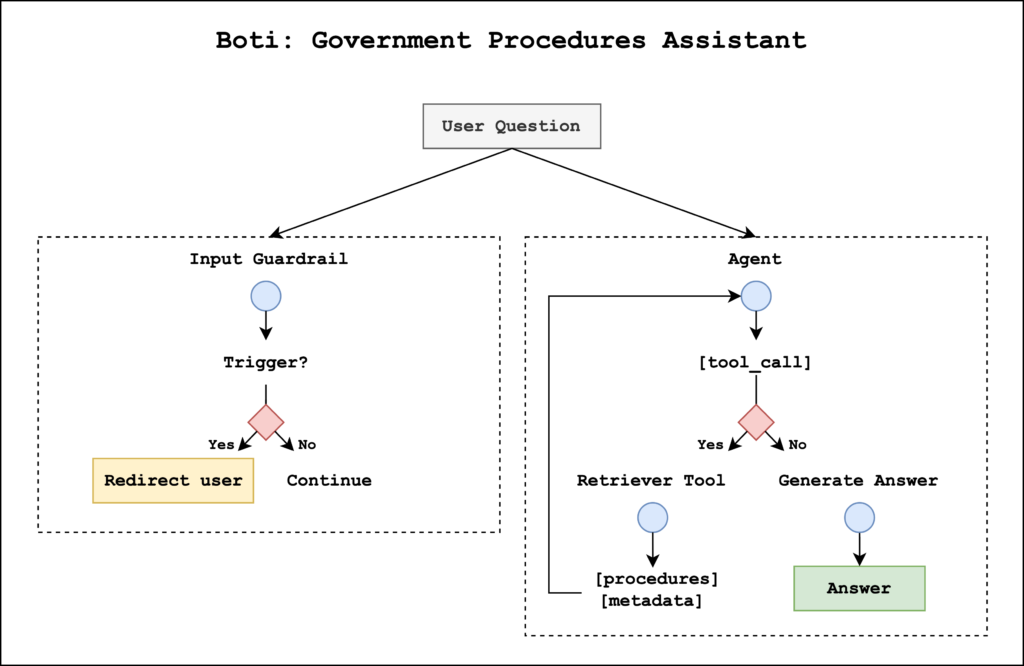
This post is co-written with Julieta Rappan, Macarena Blasi, and María Candela Blanco from the Government of the City of Buenos Aires. The Government of the City of Buenos Aires continuously works to improve citizen services. In February 2019, it introduced an AI assistant named Boti available through WhatsApp, the most widely used messaging service […]
Empowering air quality research with secure, ML-driven predictive analytics
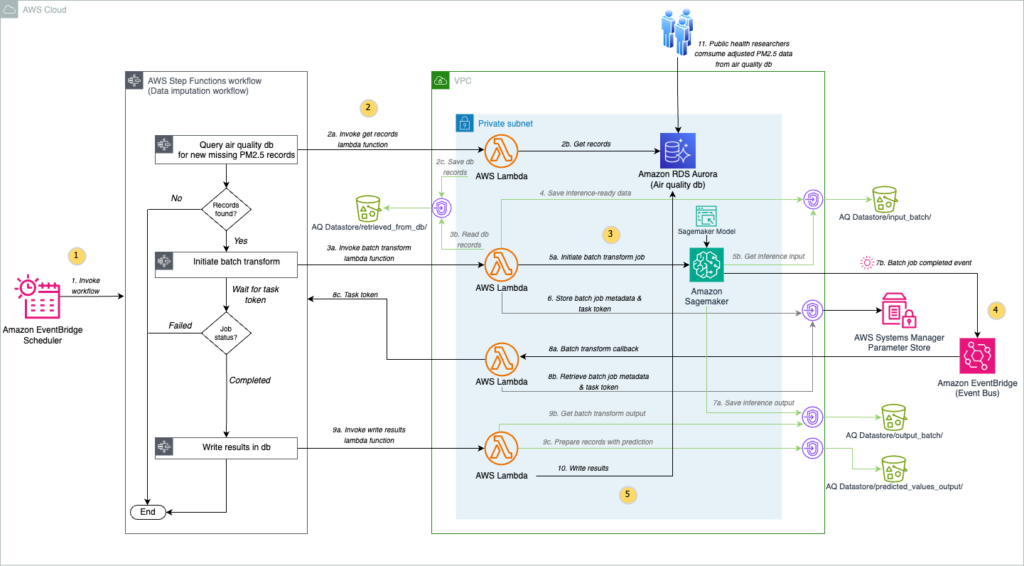
Air pollution remains one of Africa’s most pressing environmental health crises, causing widespread illness across the continent. Organizations like sensors.AFRICA have deployed hundreds of air quality sensors to address this challenge, but face a critical data problem: significant gaps in PM2.5 (particulate matter with diameter less than or equal to 2.5 micrometers) measurement records because […]
How Amazon Finance built an AI assistant using Amazon Bedrock and Amazon Kendra to support analysts for data discovery and business insights
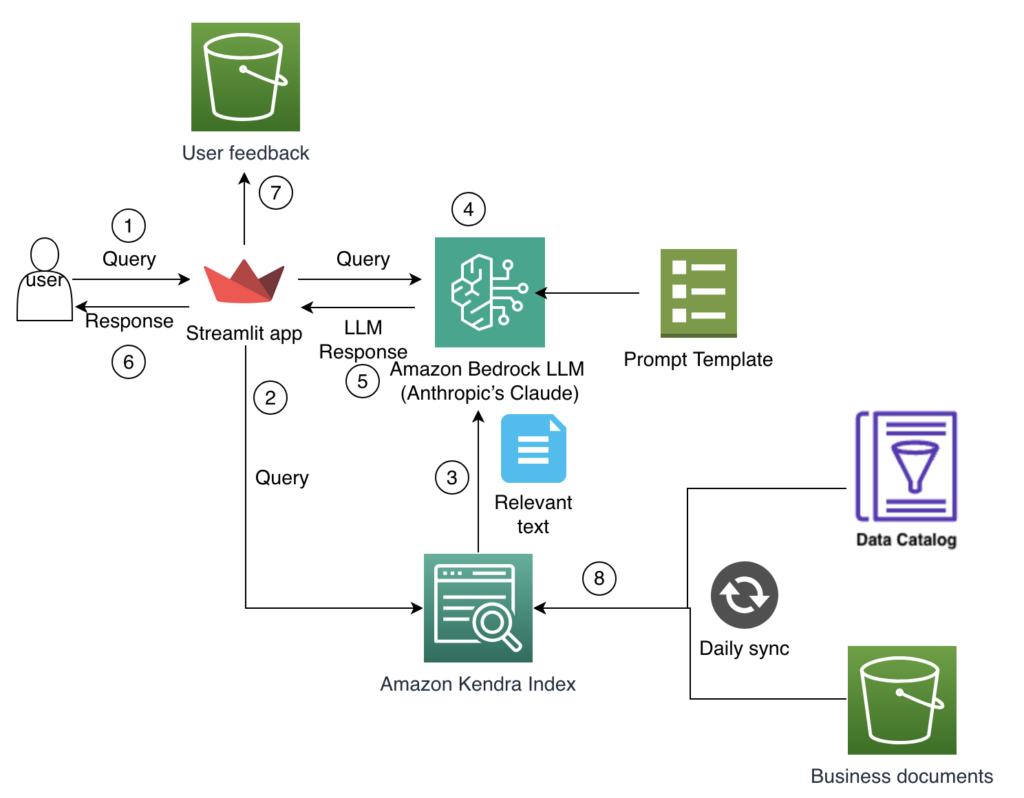
Finance analysts across Amazon Finance face mounting complexity in financial planning and analysis processes. When working with vast datasets spanning multiple systems, data lakes, and business units, analysts encounter several critical challenges. First, they spend significant time manually browsing data catalogs and reconciling data from disparate sources, leaving less time for valuable analysis and insight […]
Mercury foundation models from Inception Labs are now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
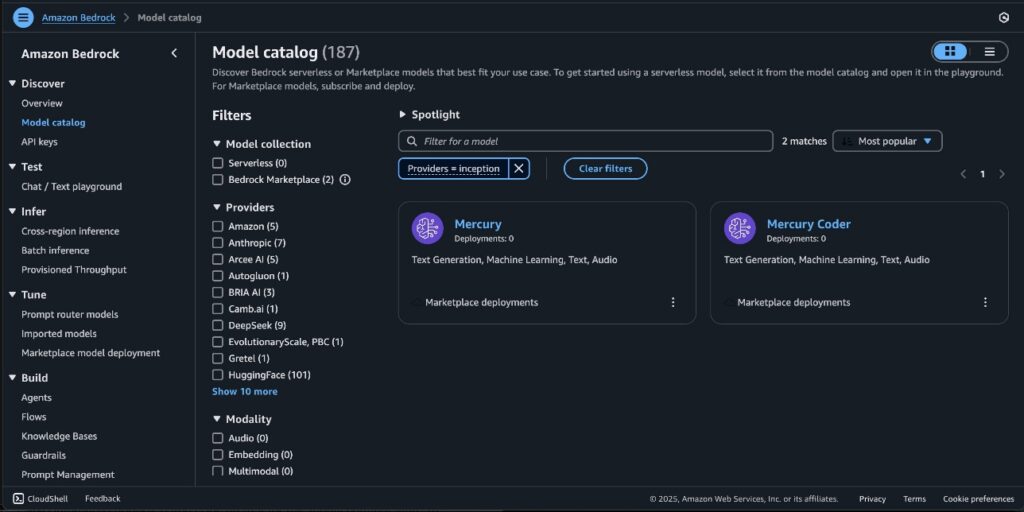
Today, we are excited to announce that Mercury and Mercury Coder foundation models (FMs) from Inception Labs are available through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, you can deploy the Mercury FMs to build, experiment, and responsibly scale your generative AI applications on AWS. In this post, we demonstrate how to […]