Enterprises across industries like healthcare, finance, manufacturing, and legal services face escalating challenges in processing vast amounts of multimodal data that combines text, images, charts, and complex technical formats. As organizations generate multimodal content at unprecedented speed and scale, document processing methods increasingly fail to handle the intricacies of specialized domains where technical terminology, interconnected data relationships, and industry-specific formats create operational bottlenecks. These conventional (non-AI) processing approaches struggle with the unique characteristics of enterprise documents: highly technical terminology, complex multimodal data formats, and interconnected information spread across various document types. This results in inefficient data extraction, missed insights, and time-consuming manual processing that hinders organizational productivity and decision-making.One such industry example is oil and gas, which generates vast amounts of complex technical data through drilling operations, presenting significant challenges in data processing and knowledge extraction. These documents, such as detailed well completion reports, drilling logs, and intricate lithology diagrams, contain crucial information that drives operational decisions and strategic planning.
To overcome such challenges, we built an advanced RAG solution using Amazon Bedrock leveraging Infosys Topaz AI capabilities, tailored for the oil and gas sector. This solution excels in handling multimodal data sources, seamlessly processing text, diagrams, and numerical data while maintaining context and relationships between different data elements. The specialized approach helps organizations unlock valuable insights from their technical documentation, streamline their workflows, and make more informed decisions based on comprehensive data analysis.
AI capabilities, tailored for the oil and gas sector. This solution excels in handling multimodal data sources, seamlessly processing text, diagrams, and numerical data while maintaining context and relationships between different data elements. The specialized approach helps organizations unlock valuable insights from their technical documentation, streamline their workflows, and make more informed decisions based on comprehensive data analysis.
In this post, we provide insights on the solution and walk you through different approaches and architecture patterns explored, like different chunking, multi-vector retrieval, and hybrid search during the development.
Solution overview
The solution is built using AWS services, including Amazon Bedrock Nova Pro, Amazon Bedrock Knowledge Bases, Amazon OpenSearch Serverless as a Vector Database, Amazon Titan Text Embeddings, Cohere Embed English model, and BGE Reranker, allowing for scalability and cost-effectiveness. We also used Amazon Q Developer, an AI-powered assistant for software development for frontend and backend development of our solution powered by Infosys Topaz’s generative AI capabilities. The solution uses distributed processing to handle large volumes of data, so the system can handle a high volume of requests without compromising performance. The real-time indexing system allows for new documents to be incorporated into the system as soon as they are available, so that the information is up-to-date.
The following are some of the key components of the solution:
- Document processing – PyMuPDF for PDF parsing, OpenCV for image processing.
- Embedding generation – Cohere Embed English on Amazon Bedrock for generating vector embeddings of document content and user queries. A hierarchical parent-child chunking architecture that preserves document structure and contextual relationships.
- Vector storage – Amazon OpenSearch Serverless for hybrid search capabilities combining semantic vector search with traditional keyword search (although Amazon Bedrock Knowledge Bases provides a managed RAG solution, this implementation uses a custom RAG architecture to deliver enhanced value and flexibility). This multi-vector retrieval mechanism with separate embedding spaces was required for maintaining the context between textual and visual data.
- Model – Amazon Nova model for domain-specific response generation.
- Reranking – BGE reranker, for improving search result relevance by reordering retrieved documents based on semantic similarity to the query.
The following diagram is a high-level overview of the architecture of the solution.
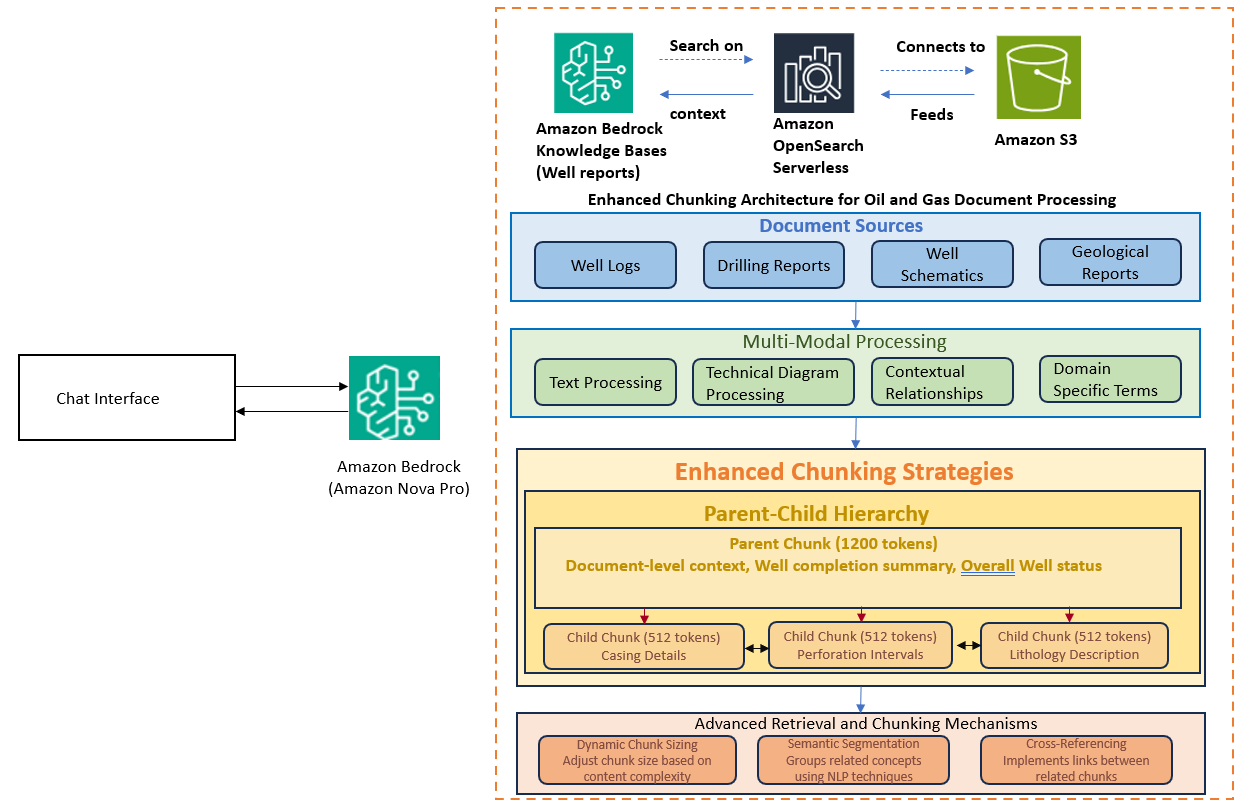
Many approaches were used during the build phase to get the desired accuracy. In the following sections, we discuss these approaches in detail.
RAG exploration and initial approach
The following figure shows some sample images from the oil and well drilling reports. The image on the left is a performance chart of a well drilling operation with the details of the drilling instrument. The image on the top right is of the split sections of the drilling instrument, followed below by the drilling data in a tabular form.
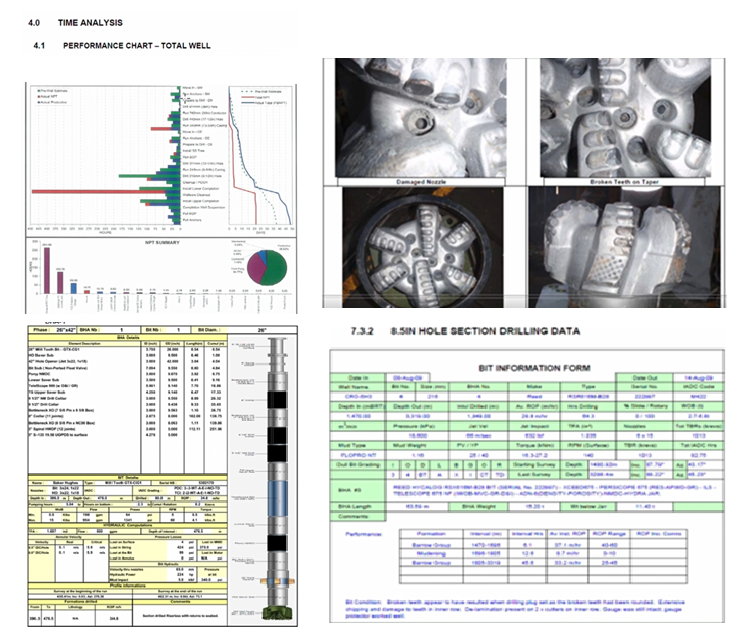
Image Source : Wells Search | NEATS
© Commonwealth of Australia [year of publishing- 2018]
Over a thousand such technical images (including lithology diagrams, well completion charts, and drilling visualizations) were preprocessed using Amazon Nova Pro, a multimodal language model. An iterative prompting strategy was employed to generate comprehensive descriptions:
- Initial image analysis to extract basic technical elements
- Refined prompting with domain-specific context to capture specialized terminology
- Multiple inference iterations to provide completeness and accuracy of technical descriptions
This process converted visual technical information into detailed textual descriptions that preserve the original technical context.The process included the following key components:
- Text content processing – The textual content from drilling reports was processed using Amazon Titan Text Embedding v2 model with:
- Fixed-size chunking of 1,500 tokens with 100-token overlap
- Preservation of original document structure and technical relationships
- Image content integration– The detailed image descriptions generated were integrated without chunking to maintain complete technical context
- Vector storage – The processed content (chunked text and complete image descriptions) was ingested into an OpenSearch Serverless vector database
- RAG implementation – RAG-enabled semantic search and retrieval is used across both textual content and image-derived descriptions
This approach worked well with text questions but was less effective with image-related questions and finding information from images. The lack of a chunking strategy for images resulted in the entire description of each image ingested as a single unit into the search index. This made it difficult for the embedding model to pinpoint exact locations of specific information, especially for technical terms that might be buried within longer descriptions.In the following sections, we discuss the other approaches explored to overcome the limitations presented by each of the previous approaches.
Multi-vector embeddings with ColBERT
To use a vision model, we created multi-vector embeddings for each image. We then used the ColBERT embedding model for fine-grained text representations. User queries were converted into embeddings, and similarity scores between query and document embeddings were calculated. These embeddings were stored using tensor-based storage, and no chunking was applied. We observed the following:
- Outcome – We encountered difficulties in storing and managing the complex ColBERT embeddings in traditional vector stores. Debugging and analyzing retrieved documents became cumbersome. Despite context-rich queries, selecting the proper document pages remained challenging.
Limitations and key learnings – This approach demonstrated the potential of advanced embedding techniques for image-based document retrieval. However, it also highlighted the challenges in implementing and managing such a system effectively, particularly in the complex domain of oil and gas. Overall, the use of vision models enhanced document understanding, and fine-grained representation of visual and textual content was achieved.
Fixed chunking with Amazon Titan Embeddings
Adopting a more traditional text-based approach, we introduced a fixed chunking strategy. PDF pages were converted to images, and text content was extracted from these images. A fixed chunking strategy of 500 tokens per chunk was implemented. We used Amazon Bedrock Knowledge Bases with OpenSearch Serverless vector storage, upgraded to Amazon Titan Embeddings v2, and retained the Amazon Nova Pro model. We observed the following:
- Outcome – The ability to find and retrieve information based on technical keyword searches improved. More focused chunks allowed for a more accurate representation of specific concepts.
- Limitations and key learnings – Providing comprehensive, long-form answers was challenging. Rigid chunking sometimes split related information across different chunks. This approach underscored the importance of balancing chunk size with information coherence, improving our handling of technical terms but highlighting the need for more sophisticated chunking strategies to maintain context.
Parent-child hierarchy with Cohere Embeddings
Building on our previous learnings, we introduced a more sophisticated chunking strategy using a parent-child hierarchy. PDF pages were converted to images and text was extracted. We implemented a parent-child chunking hierarchy with parent chunks of 1,500 tokens and child chunks of 512 tokens. We switched to Cohere English embeddings, used Amazon Bedrock Knowledge Bases and OpenSearch Serverless vector storage, and continued using the Amazon Nova Pro model. We observed the following:
- Outcome – This approach balanced the need for context with the ability to pinpoint specific information. It significantly improved the ability to answer a wide range of queries, maintaining context while offering precise information retrieval.
- Limitations and key learnings – Careful structuring of content significantly enhanced the performance of both embedding and QnA models. The parent-child structure proved particularly effective for handling the complex, nested nature of oil and gas documentation.
Hybrid search with optimized chunking
Our final approach retained the advanced features of the previous method while introducing a crucial change in the search methodology. PDF pages were converted to images and text was extracted. We implemented a hybrid search system within the Amazon Bedrock knowledge base. The parent-child chunking hierarchy was retained with parent chunks of 1,200 tokens and child chunks of 512 tokens. We continued using Cohere English embeddings and the Amazon Nova Pro model, and implemented a BGE reranker to refine search results. We observed the following:
- Outcome – This approach combined the strengths of semantic search and traditional keyword-based search. It addressed the limitations of purely embedding-based searches and improved the handling of specific technical terms and exact phrases.
- Limitations and key learnings – This final approach represents a highly evolved RAG system, offering the best of both worlds: the ability to understand context and nuance through embeddings, and the precision of keyword matching for specific technical queries.
The following are some of the tangible results of the hybrid strategy:
- Average query response time: Less than 2 seconds
- Retrieval accuracy (measured against human expert baseline): 92%
- User satisfaction rating: 4.7/5 based on feedback from field engineers and geologists
Hybrid RAG approach and optimization strategy
Let’s explore the key components and strategies that make the final approach effective for oil and gas drilling reports. Each of the following sections outlines the differentiators in the solution.
Multimodal processing capabilities
The solution is designed to handle the diverse types of information found in oil and gas documents. The system processes both textual content (technical jargon, well logs, production figures) and visual elements (well schematics, seismic charts, lithology graphs) while maintaining contextual relationships between them. This makes sure that when processing a well completion report, the system can extract key parameters from text, analyze accompanying schematics, and link textual formation descriptions to their visual representations in lithology charts.For example, when processing a well completion report, the system can:
- Extract key parameters from the text (such as total depth and casing sizes)
- Analyze the accompanying well schematic
- Link textual descriptions of formations to their visual representation in lithology charts
Domain-specific vocabulary handling
The system incorporates a comprehensive dictionary of industry terms and acronyms specific to oil and gas operations. Standard natural language processing (NLP) models often misinterpret technical terminology like “fish left in hole” or fail to recognize specialized abbreviations like “BOP” and “TVD.” By implementing domain-specific vocabulary handling, the system accurately interprets queries and maintains semantic understanding of technical concepts. This helps prevent misinterpretation of critical drilling information and provides relevant document retrieval.For example, when processing a query about “fish left in hole at 5000 ft MD,” the system understands:
- “Fish” refers to lost equipment, not an actual fish
- “MD” means measured depth
- The relevance of this information to drilling operations and potential remediation steps
Hybrid hierarchy chunking strategy
Traditional fixed-size chunking often breaks apart related technical information, losing critical context in oil and gas documents. The solution implements a hybrid hierarchy approach with parent chunks (1,200 tokens) maintaining document-level context and child chunks (512 tokens) containing detailed technical information. Dynamic chunk sizing adjusts based on content complexity, using natural language processing to identify logical break points. This preserves the integrity of technical descriptions while enabling precise information retrieval across large, complex documents.For example, when processing a well completion report, the system will:
- Create a large parent chunk for the overall well summary
- Generate smaller child chunks for specific sections like casing details or perforation intervals
- Dynamically adjust chunk size for the lithology description based on its complexity
- Implement cross-references between the casing schedule and the well schematic description
Multi-vector retrieval implementation
Oil and gas documents contain diverse content types that require different retrieval approaches. The system creates separate embedding spaces for text, diagrams, and numerical data, implementing dense vector search for semantic similarity and sparse vector search for exact technical terminology matches. Cross-modal retrieval connects information across different content types, and contextual query expansion automatically includes relevant industry-specific terms. This hybrid approach delivers comprehensive retrieval whether users search for conceptual information or specific technical parameters.For example, for a query like “recent gas shows in Permian Basin wells,” the system will:
- Use dense vector search to understand the concept of “gas shows”
- Use sparse vector search to find exact matches for “Permian Basin”
- Expand the query to include related terms like “hydrocarbon indicators”
- Apply temporal filtering to focus on recent reports
- Use spatial awareness to limit results to the Permian Basin area
Temporal and spatial awareness
Drilling operations are inherently tied to specific locations and time periods, making context crucial for accurate information retrieval. The system incorporates understanding of well locations and operational timelines, allowing for queries that consider geographical and chronological contexts. For example, searching for “recent gas shows in Permian Basin wells” uses both temporal filtering and spatial awareness to provide relevant, location-specific results. This optimization makes sure retrieved information matches the operational context of the user’s needs.For example, when generating a response about drilling fluid properties, the system will:
- Retrieve relevant information from multiple sources
- Cross-check numerical values for consistency
- Use reflective prompting to make sure critical parameters are addressed
- Apply the reranking model to prioritize the most relevant and accurate information
- Present the response along with confidence scores and source citations
Reflective response generation
Technical accuracy is paramount in oil and gas operations, where incorrect information can have serious consequences. The system implements reflective prompting mechanisms that prompt the language model to critically evaluate its own responses against source documents and industry standards. Response reranking uses scoring models that evaluate technical accuracy, contextual relevance, and adherence to industry best practices. This multi-layered validation approach makes sure generated responses meet the high accuracy standards required for technical decision-making in drilling operations.
Advanced RAG strategies
To further enhance our system’s capabilities, we implemented several advanced RAG strategies:
- Hypothetical document embeddings:
- Generates synthetic questions based on document content
- Creates embeddings for these hypothetical questions
- Improves retrieval for complex, multi-part queries
- Particularly effective for handling what-if scenarios in drilling operations
- Recursive retrieval:
- Implements multi-hop information gathering
- Allows the system to follow chains of related information across multiple documents
- Essential for answering complex queries that require synthesizing information from various sources
- Semantic routing:
- Intelligently routes queries to appropriate knowledge bases or document subsets
- Optimizes search efficiency by focusing on the most relevant data sources
- Crucial for handling the diverse types of documents in oil and gas operations
- Query transformation:
- Automatically refines and reformulates user queries for optimal retrieval
- Applies industry-specific knowledge to interpret ambiguous terms
- Breaks down complex queries into series of simpler, more targeted searches
For example, for a complex query like “Compare the production decline rates of horizontal wells in the Eagle Ford to those in the Bakken over the last 5 years,” the system will:
- Use hypothetical document embeddings to generate relevant sub-questions about decline rates, horizontal wells, and specific formations
- Apply recursive retrieval to gather data from production reports, geological surveys, and economic analyses
- Route different aspects of the query to appropriate knowledge bases (such as separate databases for Eagle Ford and Bakken data)
- Transform the query into a series of more specific searches, considering factors like well completion techniques and reservoir characteristics
Business outcome
The implementation of this advanced RAG solution has delivered significant business value for oil and gas operations:
- Operational efficiency – Significant reduction in decision-making time for drilling and field engineers
- Cost optimization – 40–50% decrease in manual document processing costs through automated information extraction
- Enhanced productivity – Field engineers and geologists spend 60% less time searching for technical information, focusing instead on high-value analysis
- Risk mitigation – Consistent 92% retrieval accuracy provides reliable access to critical technical knowledge, reducing operational decision risks
Conclusion
Our journey in developing this advanced RAG solution for the oil and gas industry demonstrates the power of combining AI techniques with domain-specific knowledge. By addressing the unique challenges of technical documentation in this field, we have created a system that not only retrieves information but understands and synthesizes it in a way that adds real value to operations. Amazon Bedrock is at the center of this solution, with Amazon Q Developer for the application frontend and backend development, and capabilities from Infosys Topaz – an AI-first offering that accelerates business value for enterprises using generative AI.We see significant potential for further advancement, s in this area, such as integration with real-time sensor data for dynamic information retrieval, enhanced visualization capabilities for complex geological and engineering data, and predictive analytics by combining historical retrieval patterns with operational data.
For more information on Amazon Bedrock and the latest Amazon Nova models, refer to the Amazon Bedrock User Guide and Amazon Nova User Guide.
About the Authors
 Dhiraj Thakur is a Solutions Architect with Amazon Web Services, specializing in Generative AI and data analytics domains. He works with AWS customers and partners to architect and implement scalable analytics platforms and AI-driven solutions. With deep expertise in Generative AI services and implementation, end-to-end machine learning implementation, and cloud-native data architectures, he helps organizations harness the power of GenAI and analytics to drive business transformation. He can be reached via LinkedIn.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services, specializing in Generative AI and data analytics domains. He works with AWS customers and partners to architect and implement scalable analytics platforms and AI-driven solutions. With deep expertise in Generative AI services and implementation, end-to-end machine learning implementation, and cloud-native data architectures, he helps organizations harness the power of GenAI and analytics to drive business transformation. He can be reached via LinkedIn.
 Meenakshi Venkatesan is a Principal Consultant at Infosys and a part of the AWS partnerships team at Infosys Topaz CoE. She helps in designing, developing, and deploying in AWS environments and has interests in exploring the new offerings and services.
Meenakshi Venkatesan is a Principal Consultant at Infosys and a part of the AWS partnerships team at Infosys Topaz CoE. She helps in designing, developing, and deploying in AWS environments and has interests in exploring the new offerings and services.
 Keerthi Prasad is a Senior Technology Architect at Infosys and a part of the AWS partnerships team at Infosys Topaz CoE. He provides guidance and assistance to customers in building various solutions in the AWS Cloud. He also supports AWS partners and customers in their generative AI adoption journey.
Keerthi Prasad is a Senior Technology Architect at Infosys and a part of the AWS partnerships team at Infosys Topaz CoE. He provides guidance and assistance to customers in building various solutions in the AWS Cloud. He also supports AWS partners and customers in their generative AI adoption journey.
 Suman Debnath is an Associate Principal at Infosys and a part of Infosys Topaz delivery. He has played multiple roles, such as architect, program manager, and data scientist, building scalable enterprise systems and AI/ML and generative AI applications on the cloud for oil and gas, healthcare, and financial clients.
Suman Debnath is an Associate Principal at Infosys and a part of Infosys Topaz delivery. He has played multiple roles, such as architect, program manager, and data scientist, building scalable enterprise systems and AI/ML and generative AI applications on the cloud for oil and gas, healthcare, and financial clients.
 Ganesh is a Enterprise Architect and Data Scientist at Infosys and part of Topaz Delivery. He has a master’s degree in computer science and machine learning. He has played multiple roles such as architect, program manager and data scientist building scalable enterprise systems.
Ganesh is a Enterprise Architect and Data Scientist at Infosys and part of Topaz Delivery. He has a master’s degree in computer science and machine learning. He has played multiple roles such as architect, program manager and data scientist building scalable enterprise systems.
 Yash Sharma is a Digital Specialist Engineer with Infosys and part of the AWS team at ICETS with a passion for emerging generative AI services. He has successfully led and contributed to numerous generative AI projects. He is always eager to expand his knowledge and stay ahead of industry trends, bringing the latest insights and techniques to work.
Yash Sharma is a Digital Specialist Engineer with Infosys and part of the AWS team at ICETS with a passion for emerging generative AI services. He has successfully led and contributed to numerous generative AI projects. He is always eager to expand his knowledge and stay ahead of industry trends, bringing the latest insights and techniques to work.
 Karthikeyan Senthilkumar is a Senior Systems Engineer at Infosys and a part of the AWSCOE at iCETS. He specializes in AWS services with a focus on emerging technologies.
Karthikeyan Senthilkumar is a Senior Systems Engineer at Infosys and a part of the AWSCOE at iCETS. He specializes in AWS services with a focus on emerging technologies.