Boost cold-start recommendations with vLLM on AWS Trainium
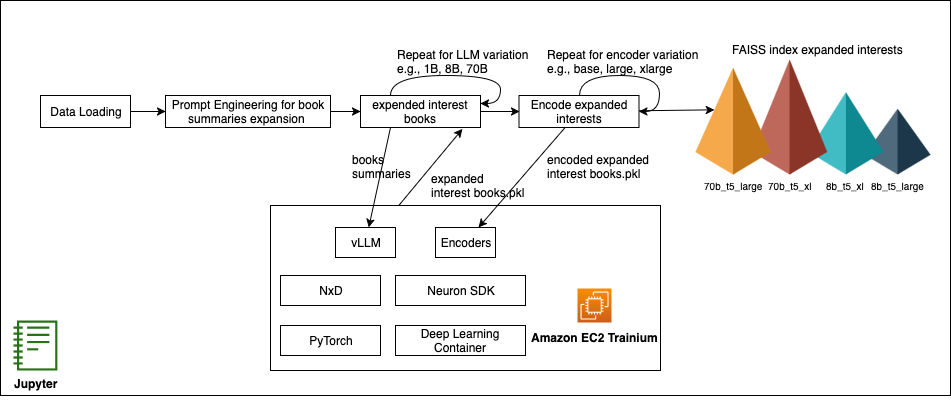
Cold start in recommendation systems goes beyond just new user or new item problems—it’s the complete absence of personalized signals at launch. When someone first arrives, or when fresh content appears, there’s no behavioral history to tell the engine what they care about, so everyone ends up in broad generic segments. That not only dampens […]
Benchmarking Amazon Nova: A comprehensive analysis through MT-Bench and Arena-Hard-Auto
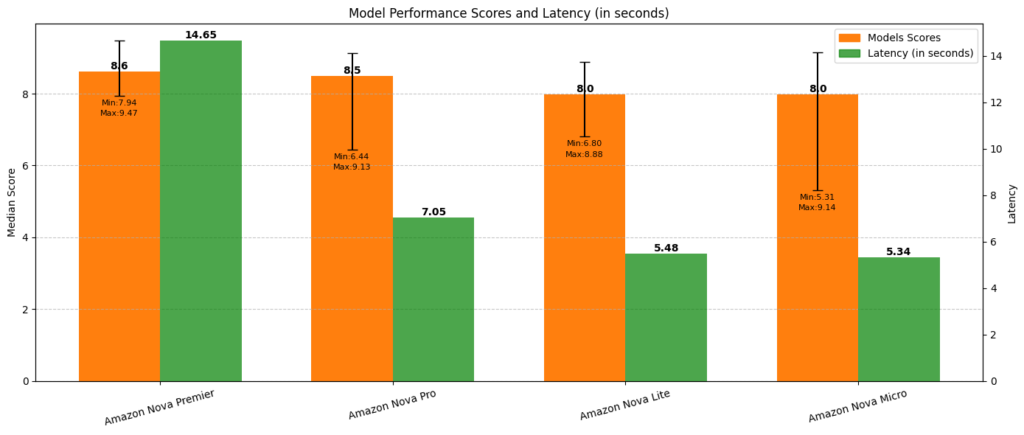
Large language models (LLMs) have rapidly evolved, becoming integral to applications ranging from conversational AI to complex reasoning tasks. However, as models grow in size and capability, effectively evaluating their performance has become increasingly challenging. Traditional benchmarking metrics like perplexity and BLEU scores often fail to capture the nuances of real-world interactions, making human-aligned evaluation […]