Evaluating generative AI models with Amazon Nova LLM-as-a-Judge on Amazon SageMaker AI
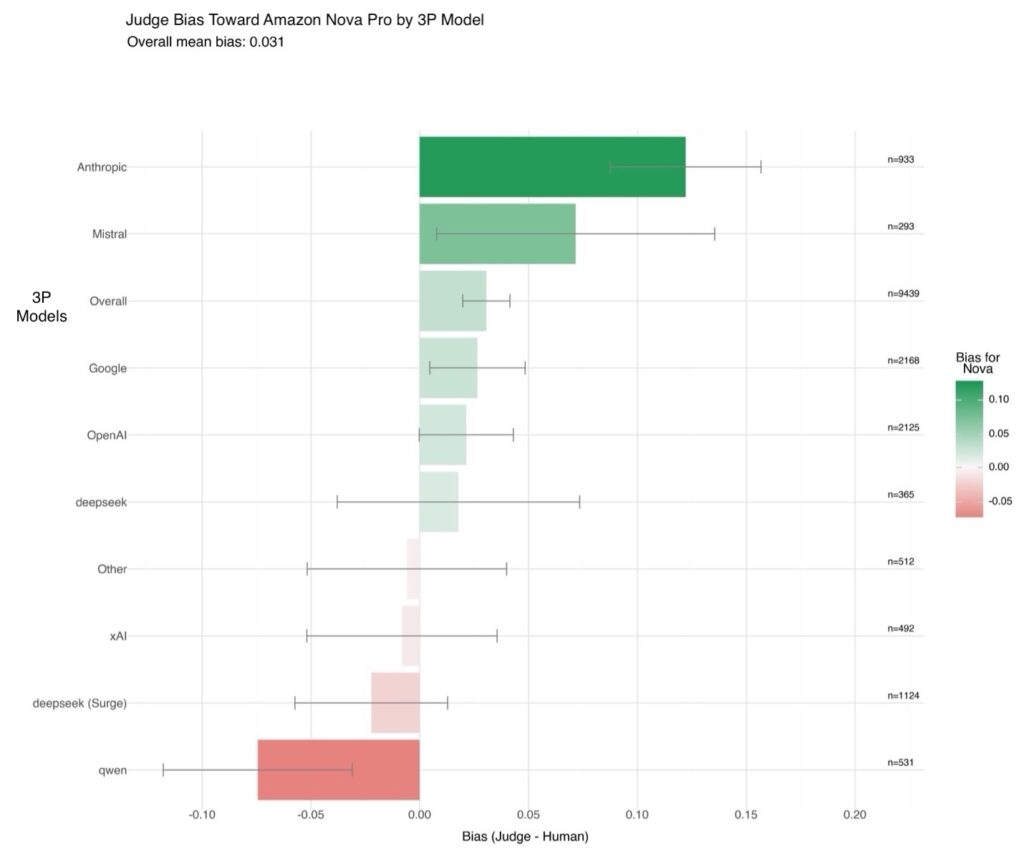
Evaluating the performance of large language models (LLMs) goes beyond statistical metrics like perplexity or bilingual evaluation understudy (BLEU) scores. For most real-world generative AI scenarios, it’s crucial to understand whether a model is producing better outputs than a baseline or an earlier iteration. This is especially important for applications such as summarization, content generation, […]
Building cost-effective RAG applications with Amazon Bedrock Knowledge Bases and Amazon S3 Vectors
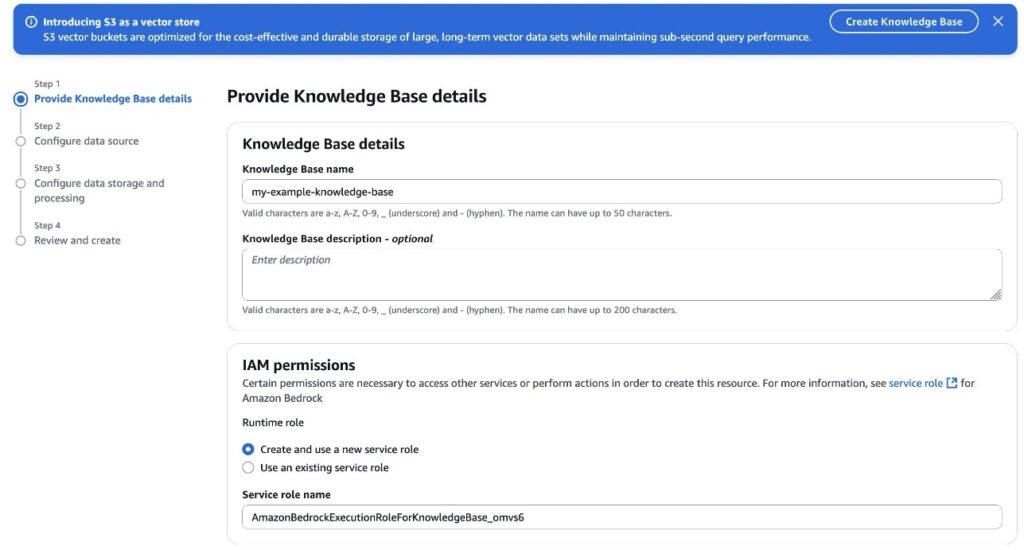
Vector embeddings have become essential for modern Retrieval Augmented Generation (RAG) applications, but organizations face significant cost challenges as they scale. As knowledge bases grow and require more granular embeddings, many vector databases that rely on high-performance storage such as SSDs or in-memory solutions become prohibitively expensive. This cost barrier often forces organizations to limit […]
Implementing on-demand deployment with customized Amazon Nova models on Amazon Bedrock
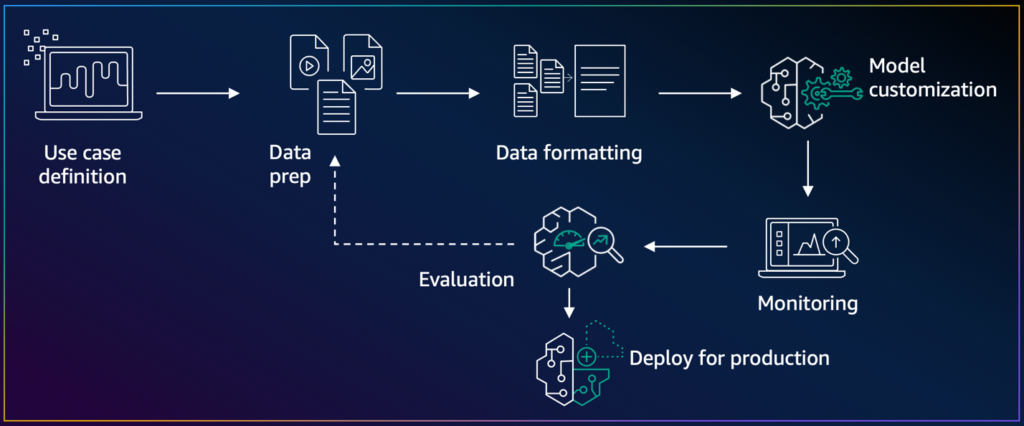
Amazon Bedrock offers model customization capabilities for customers to tailor versions of foundation models (FMs) to their specific needs through features such as fine-tuning and distillation. Today, we’re announcing the launch of on-demand deployment for customized models ready to be deployed on Amazon Bedrock. On-demand deployment for customized models provides an additional deployment option that […]
Building enterprise-scale RAG applications with Amazon S3 Vectors and DeepSeek R1 on Amazon SageMaker AI
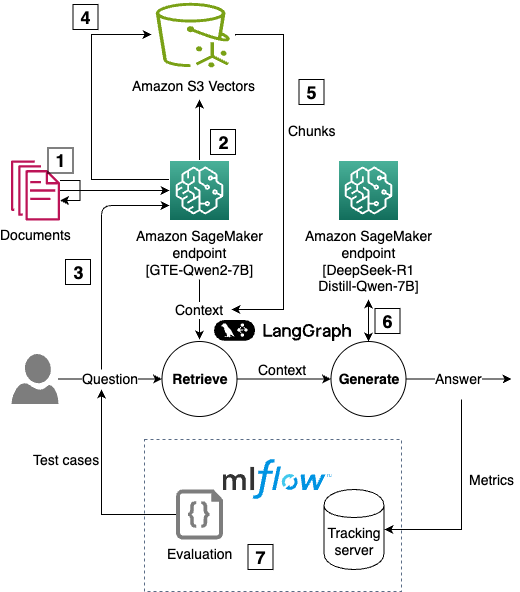
Organizations are adopting large language models (LLMs), such as DeepSeek R1, to transform business processes, enhance customer experiences, and drive innovation at unprecedented speed. However, standalone LLMs have key limitations such as hallucinations, outdated knowledge, and no access to proprietary data. Retrieval Augmented Generation (RAG) addresses these gaps by combining semantic search with generative AI, […]