Part 3: Building an AI-powered assistant for investment research with multi-agent collaboration in Amazon Bedrock and Amazon Bedrock Data Automation
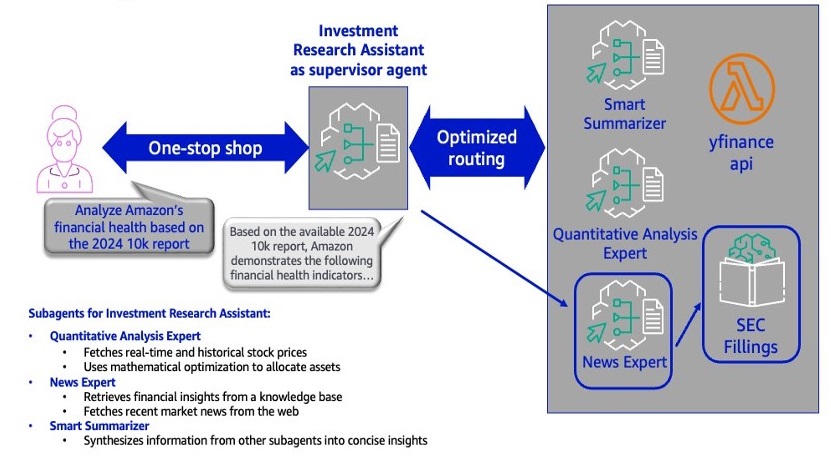
In the financial services industry, analysts need to switch between structured data (such as time-series pricing information), unstructured text (such as SEC filings and analyst reports), and audio/visual content (earnings calls and presentations). Each format requires different analytical approaches and specialized tools, creating workflow inefficiencies. Add on top of this the intense time pressure resulting […]
A generative AI prototype with Amazon Bedrock transforms life sciences and the genome analysis process
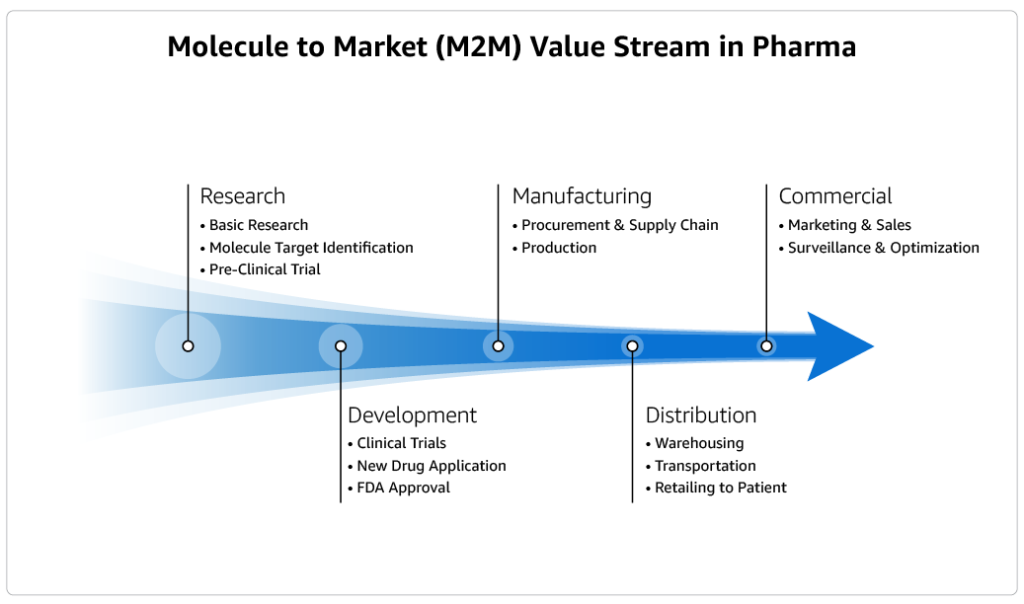
It takes biopharma companies over 10 years, at a cost of over $2 billion and with a failure rate of over 90%, to deliver a new drug to patients. The Market to Molecule (M2M) value stream process, which biopharma companies must apply to bring new drugs to patients, is resource-intensive, lengthy, and highly risky. Nine […]
Gemma 3 27B model now available on Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
We are excited to announce the availability of Gemma 3 27B Instruct models through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, developers and data scientists can now deploy Gemma 3, a 27-billion-parameter language model, along with its specialized instruction-following versions, to help accelerate building, experimentation, and scalable deployment of generative AI solutions […]
Building a multimodal RAG based application using Amazon Bedrock Data Automation and Amazon Bedrock Knowledge Bases
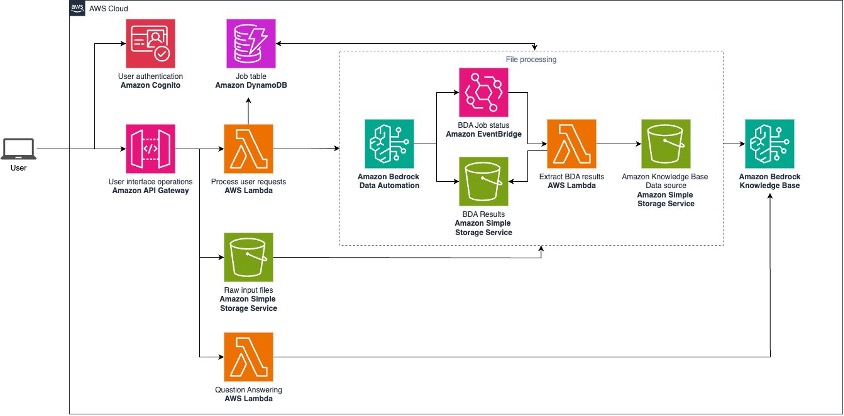
Organizations today deal with vast amounts of unstructured data in various formats including documents, images, audio files, and video files. Often these documents are quite large, creating significant challenges such as slower processing times and increased storage costs. Extracting meaningful insights from these diverse formats in the past required complex processing pipelines and significant development […]
Tailoring foundation models for your business needs: A comprehensive guide to RAG, fine-tuning, and hybrid approaches

Foundation models (FMs) have revolutionised AI capabilities, but adopting them for specific business needs can be challenging. Organizations often struggle with balancing model performance, cost-efficiency, and the need for domain-specific knowledge. This blog post explores three powerful techniques for tailoring FMs to your unique requirements: Retrieval Augmented Generation (RAG), fine-tuning, and a hybrid approach combining […]
How Rufus doubled their inference speed and handled Prime Day traffic with AWS AI chips and parallel decoding
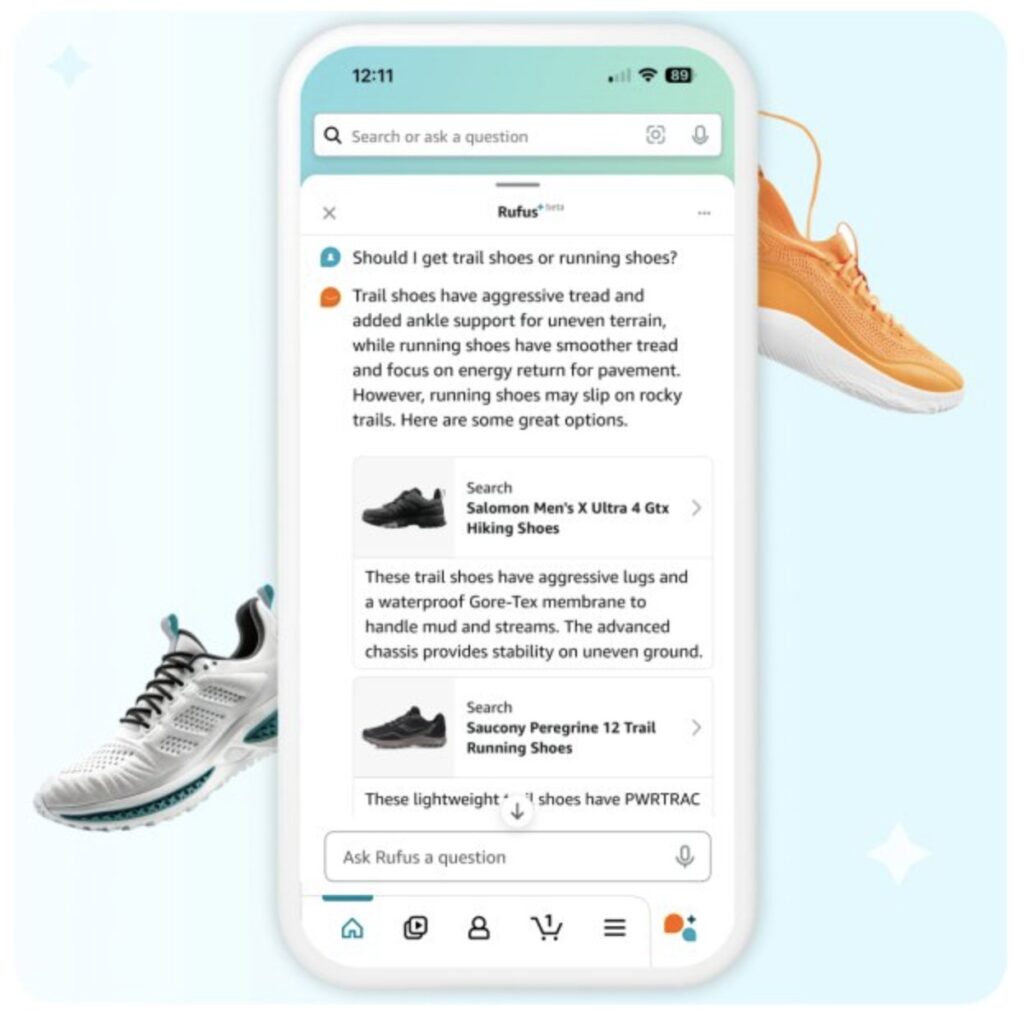
Large language models (LLMs) have revolutionized the way we interact with technology, but their widespread adoption has been blocked by high inference latency, limited throughput, and high costs associated with text generation. These inefficiencies are particularly pronounced during high-demand events like Amazon Prime Day, where systems like Rufus—the Amazon AI-powered shopping assistant—must handle massive scale […]