Easily deploy and manage hundreds of LoRA adapters with SageMaker efficient multi-adapter inference
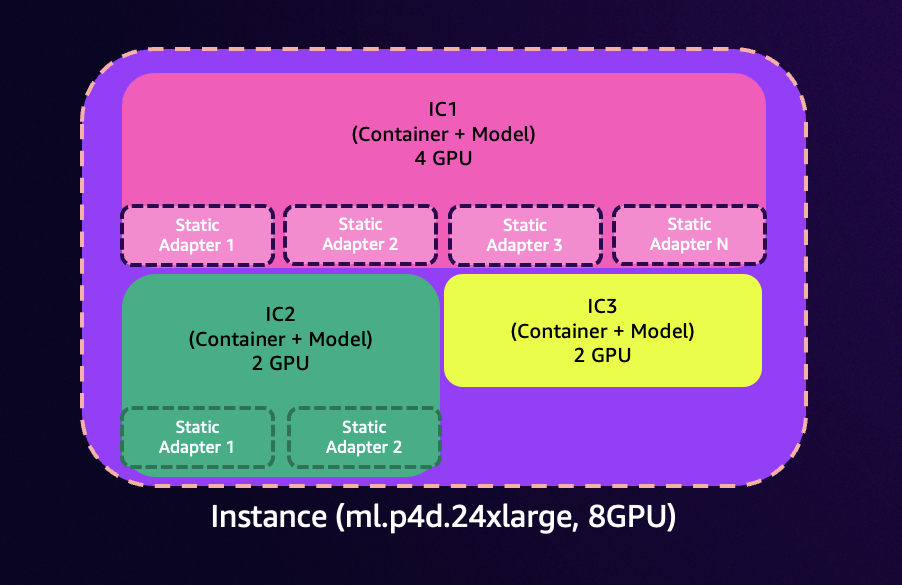
The new efficient multi-adapter inference feature of Amazon SageMaker unlocks exciting possibilities for customers using fine-tuned models. This capability integrates with SageMaker inference components to allow you to deploy and manage hundreds of fine-tuned Low-Rank Adaptation (LoRA) adapters through SageMaker APIs. Multi-adapter inference handles the registration of fine-tuned adapters with a base model and dynamically […]
Improve the performance of your Generative AI applications with Prompt Optimization on Amazon Bedrock
Prompt engineering refers to the practice of writing instructions to get the desired responses from foundation models (FMs). You might have to spend months experimenting and iterating on your prompts, following the best practices for each model, to achieve your desired output. Furthermore, these prompts are specific to a model and task, and performance isn’t […]