Unleash your Salesforce data using the Amazon Q Salesforce Online connector
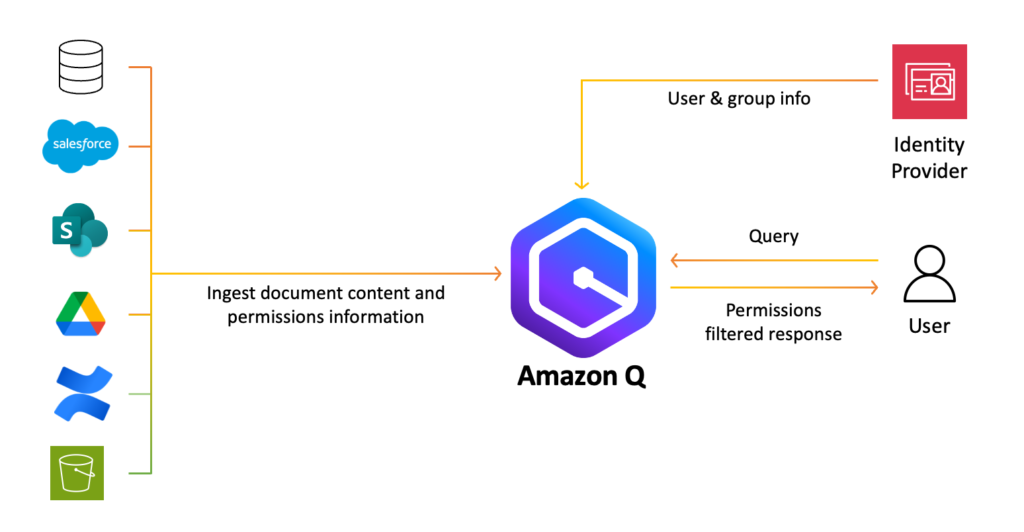
Thousands of companies worldwide use Salesforce to manage their sales, marketing, customer service, and other business operations. The Salesforce cloud-based platform centralizes customer information and interactions across the organization, providing sales reps, marketers, and support agents with a unified 360-degree view of each customer. With Salesforce at the heart of their business, companies accumulate vast […]
Reducing hallucinations in large language models with custom intervention using Amazon Bedrock Agents
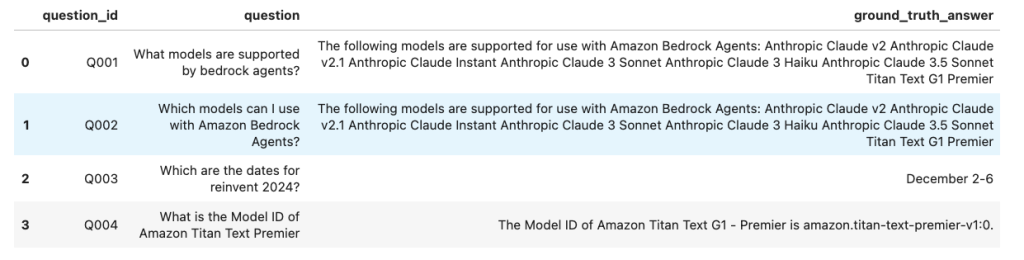
Hallucinations in large language models (LLMs) refer to the phenomenon where the LLM generates an output that is plausible but factually incorrect or made-up. This can occur when the model’s training data lacks the necessary information or when the model attempts to generate coherent responses by making logical inferences beyond its actual knowledge. Hallucinations arise […]
Deploy Meta Llama 3.1-8B on AWS Inferentia using Amazon EKS and vLLM

With the rise of large language models (LLMs) like Meta Llama 3.1, there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently […]
Serving LLMs using vLLM and Amazon EC2 instances with AWS AI chips
The use of large language models (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance […]
Using LLMs to fortify cyber defenses: Sophos’s insight on strategies for using LLMs with Amazon Bedrock and Amazon SageMaker
This post is co-written with Adarsh Kyadige and Salma Taoufiq from Sophos. As a leader in cutting-edge cybersecurity, Sophos is dedicated to safeguarding over 500,000 organizations and millions of customers across more than 150 countries. By harnessing the power of threat intelligence, machine learning (ML), and artificial intelligence (AI), Sophos delivers a comprehensive range of […]
Enhanced observability for AWS Trainium and AWS Inferentia with Datadog
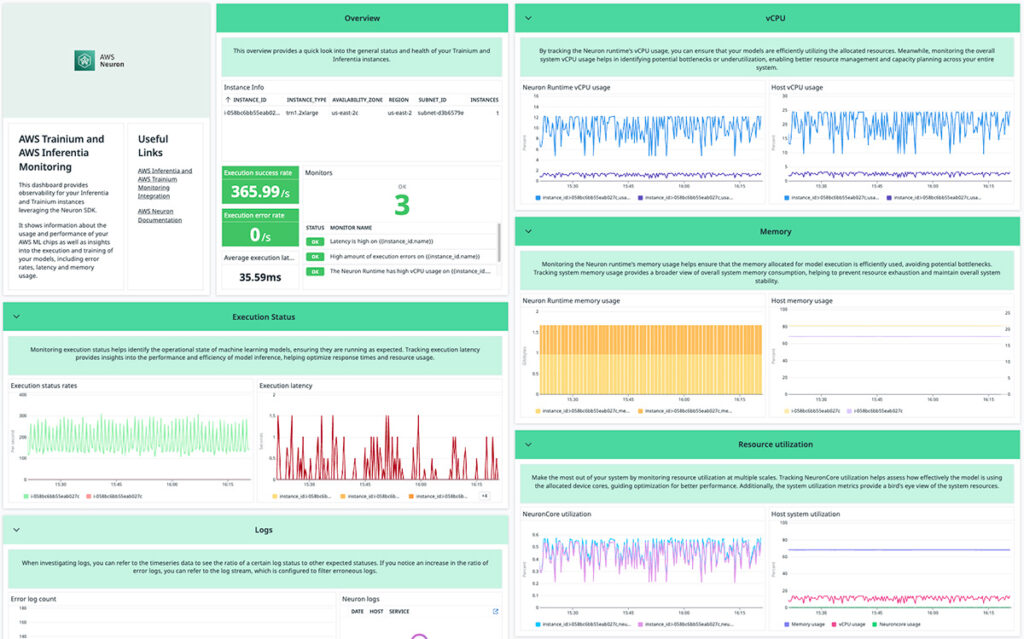
This post is co-written with Curtis Maher and Anjali Thatte from Datadog. This post walks you through Datadog’s new integration with AWS Neuron, which helps you monitor your AWS Trainium and AWS Inferentia instances by providing deep observability into resource utilization, model execution performance, latency, and real-time infrastructure health, enabling you to optimize machine learning […]
Create a virtual stock technical analyst using Amazon Bedrock Agents
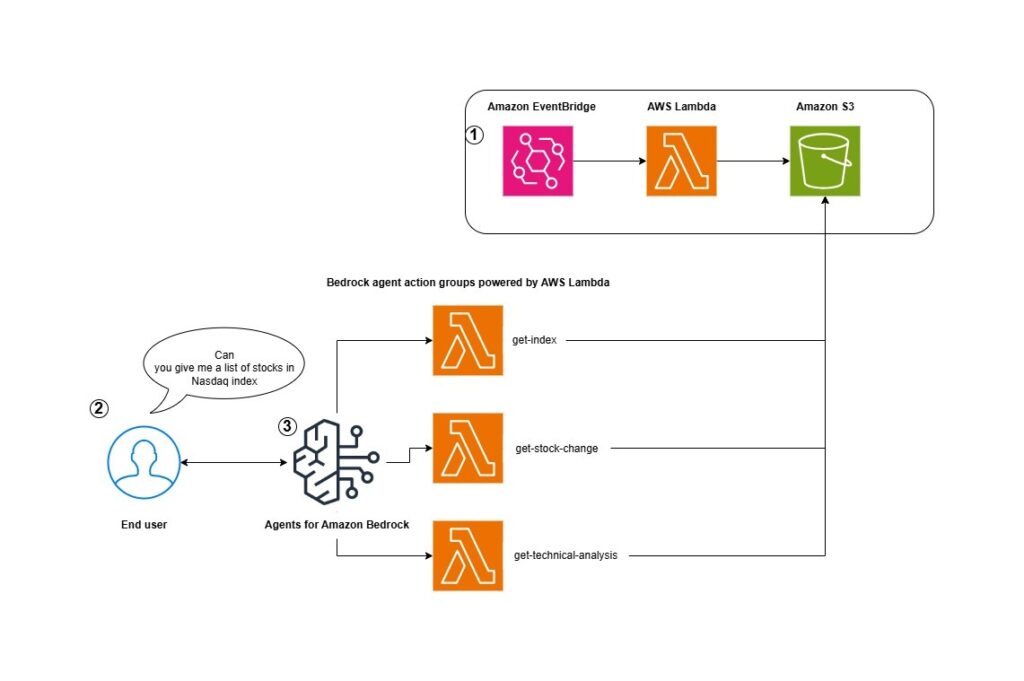
Stock technical analysis questions can be as unique as the individual stock analyst themselves. Queries often have multiple technical indicators like Simple Moving Average (SMA), Exponential Moving Average (EMA), Relative Strength Index (RSI), and others. Answering these varied questions would mean writing complex business logic to unpack the query into parts and fetching the necessary […]
Apply Amazon SageMaker Studio lifecycle configurations using AWS CDK
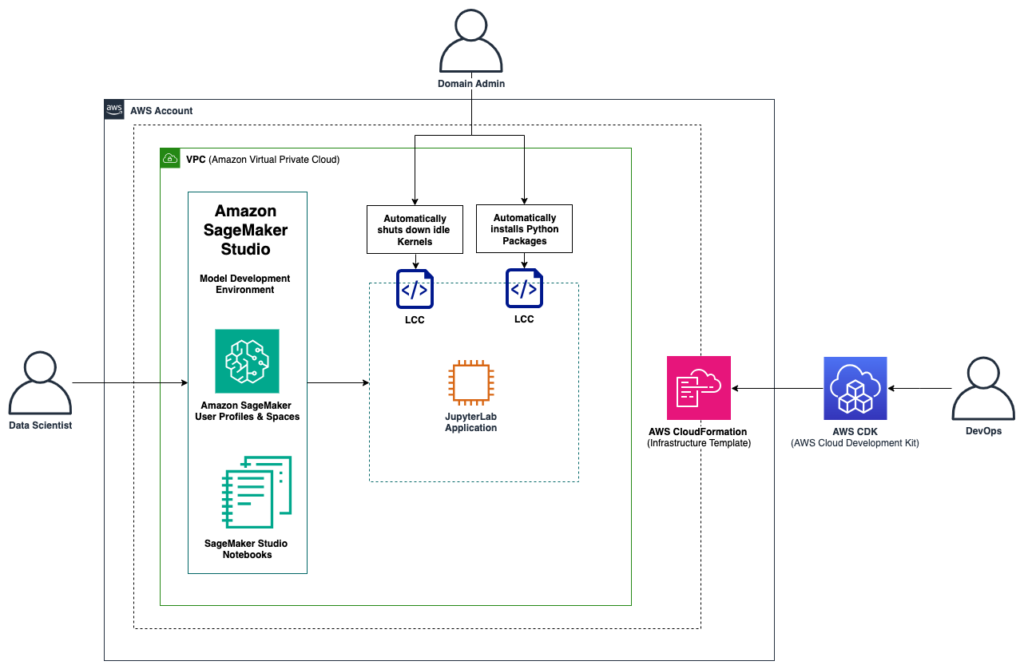
This post serves as a step-by-step guide on how to set up lifecycle configurations for your Amazon SageMaker Studio domains. With lifecycle configurations, system administrators can apply automated controls to their SageMaker Studio domains and their users. We cover core concepts of SageMaker Studio and provide code examples of how to apply lifecycle configuration to […]
Build a read-through semantic cache with Amazon OpenSearch Serverless and Amazon Bedrock
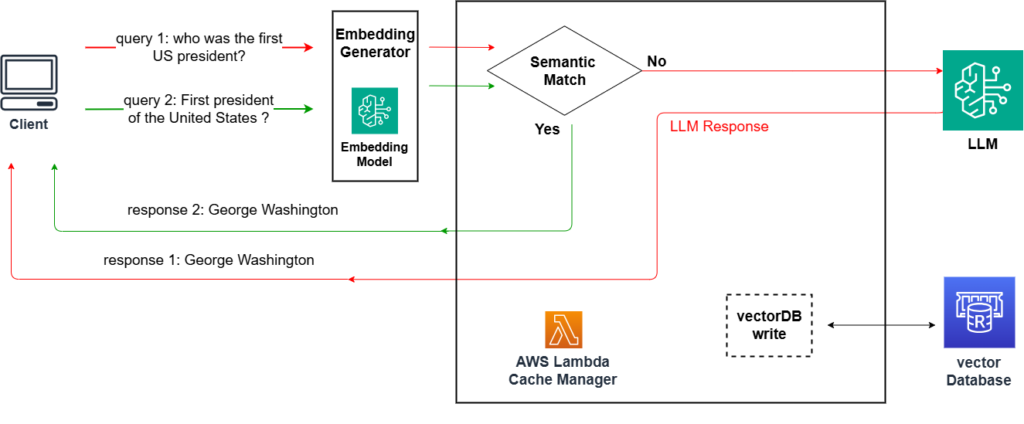
In the field of generative AI, latency and cost pose significant challenges. The commonly used large language models (LLMs) often process text sequentially, predicting one token at a time in an autoregressive manner. This approach can introduce delays, resulting in less-than-ideal user experiences. Additionally, the growing demand for AI-powered applications has led to a high […]
Rad AI reduces real-time inference latency by 50% using Amazon SageMaker
This post is co-written with Ken Kao and Hasan Ali Demirci from Rad AI. Rad AI has reshaped radiology reporting, developing solutions that streamline the most tedious and repetitive tasks, and saving radiologists’ time. Since 2018, using state-of-the-art proprietary and open source large language models (LLMs), our flagship product—Rad AI Impressions— has significantly reduced the […]